
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- #직장인영어
- 해외취업컨퍼런스
- 스몰토크
- #링글
- Ringle
- 뉴노멀챌린지
- 총각네장어
- #체험수업
- 영어시험
- 영어회화
- 장어랑고기같이
- CommunicateWiththeWorld
- 영어공부
- #링글후기
- #nlp
- 소통챌린지
- 둔촌역장어
- 강동구장어맛집
- 화상영어
- 영어공부법
- #영어발음교정
- #Ringle
- 영어로전세계와소통하기
- 오피스밋업
- 링글경험담
- 링글리뷰
- 성내동장어
- 링글커리어
- #영어공부
- 링글
- Today
- Total
Soohyun’s Machine-learning
The Annotated Transformer 번역 본문
The Annotated Transformer 번역
Alex_Rose 2021. 3. 26. 23:49※ I allowed translating and posting the article "The Annotated Transformer" to Korean by Dr. Rush.
original page : https://nlp.seas.harvard.edu/2018/04/03/attention.html
The Annotated Transformer
from IPython.display import Image Image(filename='images/aiayn.png') The Transformer from “Attention is All You Need” has been on a lot of people’s minds over the last year. Besides producing major improvements in translation quality, it provides a n
nlp.seas.harvard.edu
from IPython.display import Image
Image(filename='images/aiayn.png')
작년, "Attention is All You Need"의 트랜스포머는 많은 사람들의 마음에 들었다. 게다가 번역 품질에 있어서 주요한 발전을 만들어냈고, 많은 다른 NLP 태스크들에 새로운 아키텍쳐를 공급했다. 논문 자체는 매우 깔끔하게 쓰여져 있지만, 보편적인 지식으로 논문을 정확하게 구현하기는 어려운 점이 있다.
여기서는 한 줄 한 줄 구현해보는 형태로, 논문의 "주석달린" 버전을 보여줄것이다. 원본 논문으로부터 몇 개의 섹션을 제거하고, 순서를 조정했으며, 전체적으로 코멘트를 추가했다. 이 문서 자체는 (주피터) 노트북으로 동작하며, 완벽하게 사용가능한 구현이 되도록 했다. 4개의 GPU들이 1초에 27,000개의 토큰을 프로세싱할 수 있는, 다 합쳐서 400 줄의 라이브러리 코드가 있다.
이 과정을 따라가기 위해서는 Pytorch를 먼저 인스톨하는 작업이 필요하다. 노트북의 완성본은 깃허브 또는 구글 코랩(무료 GPU 사용 가능)에서도 볼 수 있다.
연구자들과 (머신러닝/nlp/transformer에 관심이 있는) 개발자들에게 알려두고 싶은 것은, (이 내용은) 단지 시작점일 뿐이라는 것이다. 여기에 쓰인 코드는 우리의 (이전 작업인) OpenNMT 패키지에 대부분 기반하고 있다. (도움이 되면 얼마든지 cite) 다른 전체 서비스 적용을 위해서는 Tensor2Tensor (tensorflow)와 Sockeye (mxnet)을 체크 해봐라.
- 저자 : Alexander Rush (arush at cornell.edu), Vincent Nguyen과 Guillaume Klein의 도움을 받았습니다.
준비사항 (Preliminaries)
!pip install http://download.pytorch.org/whl/cu80/torch-0.3.0.post4-cp36-cp36m-linux_x86_64.whl numpy matplotlib spacy torchtext seabornimport numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import math, copy, time
from torch.autograd import Variable
import matplotlib.pyplot as plt
import seaborn
seaborn.set_context(context="talk")
%maplotlib inline
블록으로 시작하는 주황색 글씨는 저자(A. Rush)의 코멘트입니다. 주요 텍스트들은 전부 페이퍼에서 가져왔습니다.
백그라운드 (Background)
연속적인 연산(sequential computation)을 줄이는 행위의 목적은, Extended Neural GPU, ByteNet 그리고 ConvS2S의 근원적 형태(모두가 CNN을 기본적인 building 블록으로 사용함)를 형성하고, 모든 인풋과 아웃풋 포지션들을 병행처리하는 걸로 숨겨진 표현들(hidden representations)을 계산하는 것이다.
이 모델들에서 오퍼레이션 횟수는 임의의 인풋 또는 아웃풋, 두 포지션 간의 거리에 따라 증가하며, 이와 관련있는 신호들(signals)이 요구된다, (증가하는 정도는) ConvS2S는 선형(증가) 그리고 ByteNet은 로그(증가)한다. 이것이 거리가 있는 포지션들간의 의존도를 학습하는 일을 더 어렵게 만든다.
트랜스포머에서는 (오퍼레이션 횟수를) 상수 횟수로(constant number of operations)로 줄였지만, 어텐션-가중치 포지션들(attention-weighted positions)을 평균냄으로써, 효과적인 해결책들까지 줄여버리는 문제가 발생했다, 이는 Multi-Head Attention을 사용하는 것으로 대처한다.
셀프 어텐션(Self-attention), 때로는 인트라 어텐션(intra-attention)이라고 불리우는 이것은, 시퀀스의 표현력 (representation of the sequence)를 계산하기 위한, 한 시퀀스의 서로다른 포지션들과 관련한 어텐션 매커니즘이다.
셀프 어텐션은 여러가지 태스크들에서 성공적으로 사용되었다. 독해, 요약하기, textual entailment (역자: 주어진 두 개의 문장에서 한 문장이 다른 단어와 비슷한지, 아니면 반대인지를 체크하는 것) 그리고 태스크-독립적인 문장 표현 학습 등등을 포함해서. End-to-End 메모리 네트워크는 시퀀스 맞춤 회귀(sequence aligned recurrence) 대신에 재귀 어텐션 매커니즘(recurrent attention mechanism)을 기반으로 한다. 이는 간단한 언어 질답과 언어 모델링 태스크들에서 잘 해내는 모습을 보여준 바 있다.
그러나(저자가 아는 한), 이 트랜스포머는 그 인풋과 아웃풋의 representations의 계산을 위해 셀프 어텐션에 전적으로 의존하는, 첫번째 변환 모델(transduction model)이다. 시퀀스 맞춤 RNNs (sequence aligned RNNs)이나 컨볼루션 (convolution)이 없다.
모델 아키텍쳐 (Model Architecture)
가장 경쟁력있는 신경(망) 시퀀스 변환 (neural sequence transduction) 모델들은 인코더-디코더 (encoder-decoder) 구조를 하고 있다. (cite) 인코더는 심볼 표현들의 인풋 시퀀스 (input sequence of symbol representations) $(x_{1} ,..., x_{n})$를 연속적 표현의 시퀀스 (sequence of continuous representations) $z=(z_{1} ,..., z_{n})$로 매핑한다.
z가 주어지면, 디코더는 한 번에 하나의 요소씩, 심볼들의 아웃풋 시퀀스 $(y_{1} ,..., y_{m})$를 생성한다. 각 스텝마다 모델은 자동회귀(auto-regressive)적이고 (cite), 다음 것을 생성할 때 이전에 생성된 심볼을 추가적인 인풋으로 쓴다.
class EncoderDecoder(nn.Module):
"""
보편적인 인코더-디코더 아키텍쳐입니다. 트랜스포머와 다른 많은 모델의 베이스입니다.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
"인풋을 받고, 마스킹된 소스와 타겟 시퀀스들을 처리"
return self.decode(self.encode(src, src_mask), src_mask,
tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
class Generator(nn.Module):
"보편적인 linear + softmax 생성 스텝"
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return F.log_softmax(self.proj(x), dim=-1)
트랜스포머는 인코더와 디코더 (아래 그림에서 왼쪽이 인코더, 오른쪽이 디코더) 양쪽 모두에, 쌓은(stacked) 셀프 어텐션과 point-wise, 완전 연결(fully connected) 레이어를 사용한, 이 아키텍쳐 전체를 따른다.
Image(filename='images/ModalNet-21.png')
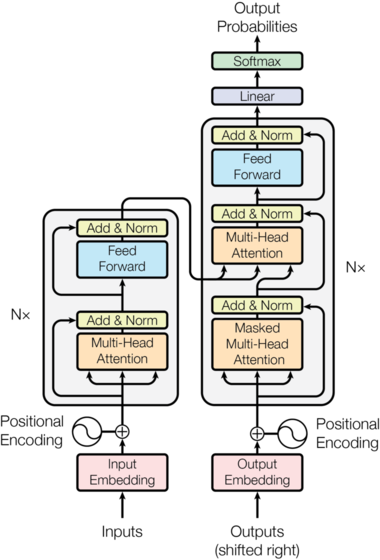
인코더와 디코더 스택 (Encoder and Decoder Stacks)
Encoder
인코더는 N=6 (즉 6개의) 동일한 레이어들의 스택으로 이루어져 있다.
def clones(module, N):
"N개의 동일한 레이어들 생성"
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])class Encoder(nn.Module):
"코어 인코더는 N개의 레이어들의 스택입니다"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"각 레이어를 통해 인풋과 마스크를 차례로 전달"
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
두 개의 서브 레이어들마다 각각 잔차 연결(residual connection) (cite)을 사용하고, 그 다음 레이어 정규화(layer normalization) (cite) 를 한다.
class LayerNorm(nn.Module):
"레이어 노말라이제이션 모듈을 만듭니다 (세부적인건 citation을 참고하세요)"
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
각 서브 레이어의 아웃풋은 $LayerNorm(x+Sublayer(x))$이다, $Sublayer(x)$는 서브 레이어 자체 구현 함수이다. 각 서브 레이어의 아웃풋에는 드롭아웃(Dropout) (cite) 을 적용한다. (서브 레이어의 인풋에 추가되기 전과 정규화 전에) 이 잔차 연결들(residual connections)의 활성화를 위해, 모델안에 있는 모든 서브 레이어들은 (물론 임베딩 레이어들도) 차원이 512, $d_{model} = 512$인 아웃풋을 만들어내야 한다.
class SublayerConnection(nn.Module):
"""
잔차 연결에 뒤이어 layer norm이 나온다
심플한 코드를 위해 norm은 마지막이 아닌 첫번째에 둔다
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"""동일한 사이즈의 서브레이어에 잔차 연결을 적용한다"""
return x + self.dropout(sublayer(self.norm(x)))
각 레이어는 두개의 서브 레이어를 갖고 있다. 첫번째는 멀티-헤드 셀프-어텐션 매커니즘(multi-head self-attention mechanism)이고, 두번째는 간단하다. 포인트와이즈(point-wise) 완전 연결(fully connected) 피드포워드(feed-forward) 네트워크이다.
class EncoderLayer(nn.Module):
"""인코더는 셀프-어텐션과 피드 포워드로 만들어진다 (하단에 정의)"""
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
"""연결을 위해 Figure 1 (왼쪽) 형태를 따른다"""
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
디코더 (Decoder)
디코더 또한 N=6개의 동일한 레이어들의 스택으로 이루어져 있다.
class Decoder(nn.Module):
"마스킹과 함께, 일반적인 N개의 레이어를 가진 디코더"
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
추가적으로 인코더 레이어에 있는 두개의 서브 레이어들을 위해, 디코더는 인코더 스택의 아웃풋에 멀티-헤드 어텐션(multi-head attention)을 수행하는 세번째 서브 레이어를 집어넣는다. 인코더와 비슷하게 각 서브 레이어들 주변에서 잔차 연결(residual connections)을 수행하고 레이어 정규화(layer normalization)를 한다.
class DecoderLayer(nn.Module):
"""디코더는 (아래처럼) 셀프 어텐션과 src-어텐션, 그리고 feed forward로 만들 수도 있다"""
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
"""연결하기 위해서 Figure 1 오른쪽을 따른다"""
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
이후의 포지션들(역자: 문장 내에서 해당 포지션 단어 뒤에 있는 단어들)이 연산에 포함되는 걸 방지하기 위해, 디코더 스택에 있는 셀프-어텐션(selt-attention) 서브 레이어도 수정하자. 마스킹(역자: 단어를 MASK로 대체), 아웃풋 임베딩들은 한 포지션의 오프셋이라는 사실과 결합해서, 포지션 i의 예측은 오로지 i보다 이전 포지션들의 결과물로만 알아낸다는 점을 확실하게 한다.
def subsequent_mask(size):
"""다음 포지션들을 mask out해준다"""
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
return torch.from_numpy(subsequent_mask) == 0하단의 어텐션 마스크는, 볼 수 있도록 허용된(연산에 포함되는, 열, column) 각 tgt 단어(행, row)의 포지션을 보여줍니다.
plt.figure(figsize=(5,5))
plt.imshow(subsequent_mask(20)[0])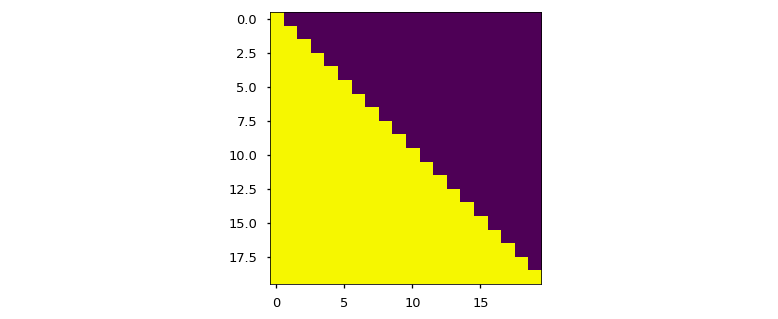
어텐션 (Attention)
어텐션 함수는 키-밸류 페어(key-value pairs)와 쿼리(query) 매핑으로 설명할 수 있을 것이다. (쿼리, 키, 밸류와 아웃풋들은 전부 벡터이다.) 아웃풋은 밸류들의 가중 합(weighted sum)으로 연산된다, 각 밸류에 지정(assign)되는 가중치는, 쿼리의 compatibility function에 의해 그에 상응하는 키(corresponding key)와 함께 연산된다.
이 특수한 어텐션을 "스케일링된 내적 어텐션(Scaled Dot-Product Attention"이라고 부른다. 인풋은 $d_{k}$의 차원을 가진 쿼리와 키, 그리고 $d_{v}$의 차원을 가진 밸류로 구성되어 있다. 쿼리와 전체 키의 내적(dot products) 연산을 하고, 각각을 $\sqrt {d_{k}}$로 나누고는 밸류에 대한 가중치를 얻기 위해서 소프트맥스 함수를 적용한다.
Image(filename='images/ModalNet-19.png')
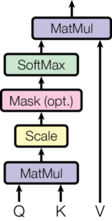
실제로는, 쿼리 세트에 대한 어텐션 함수를 동시에 연산하고, 합쳐서 행렬 Q로 만든다. 키와 밸류 또한 합쳐서 각각 행렬 K와 V가 된다. 아웃풋 매트릭스를 연산하는 건 아래와 같다.
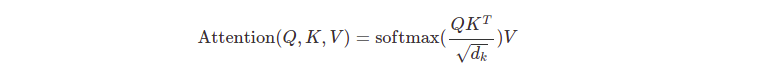
def attention(query, key, value, mask=None, dropout=None):
"'Scaled Dot Product Attention' 계산하기"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
가장 많이 쓰이는 어텐션 함수 두개는 더하기 어텐션(additive attention, cite)과 내적 어텐션(dot-product (multiplicative) attention)이다.
내적 어텐션은 스케일링 팩터인 $\frac {1} {\sqrt {d_{k}}} $ 를 제외하고는 여기 알고리즘과 동일하다.
더하기 어텐션은 하나의 히든 레이어를 가진 피드-포워드 네트워크(feed-forward network)를 사용해서 compatibility function을 연산한다. 이론적으로 보는 컴플렉시티(theoretical complexity)는 두 개가 동일하지만, 실제로는 고도로 최적화된 행렬 곱 코드 (matrix multiplication code)를 적용할 수 있는, 내적 어텐션(dot-product attention)이 훨씬 빠르고 공간-효율적(space-efficient)이다.
$d_{k}$가 작은 값들에서는 두 매커니즘이 비슷한 효율을 보여주는데, 더하기 어텐션은 $d_{k}$가 큰 값들을 스케일링하는 일이 없어서 내적 어텐션을 압도한다. (cite)
우리는 $d_{k}$의 큰 값들에 대해 의문을 가졌다, 내적은 크기가 커진다, 소프트맥스 함수(softmax function)를 극도로 작은 기울기 (extremely small gradients)를 가진 지역에 넣는다. (왜 내적이 커지는지를 설명하기 위해서, q와 k의 요소들은 mean이 0이고 variance 1을 가진 서로 독립적인 확률 변수 - random variables라고 가정한다. 그러면 이들의 내적은 $q\cdot k=\sum_{i=1}^{d_{k}}q_{i}k_{i}$이고, mean은 $0$ variance는 $d_{k}$로 가진다)
이 효과를 어느정도 상쇄하기 위해서, 내적을 $\frac{1}{\sqrt {d_{k}}}$로 스케일 조절을 해준다.
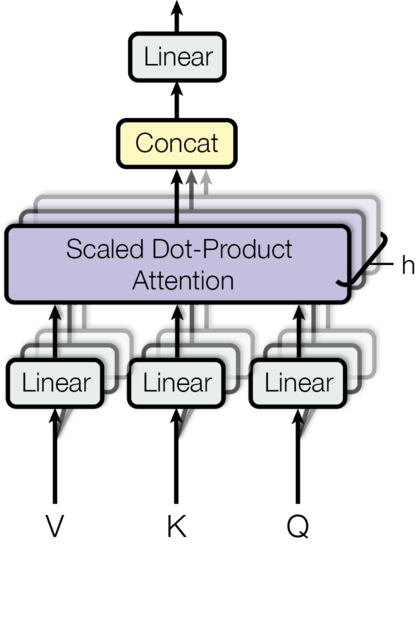
멀티-헤드 어텐션은, 다른 위치(positions)에 있는 다른 표현의 하위공간들(subspaces)로부터 오는 정보에, 모델이 함께 어텐션 (jointly attend) 할 수 있게 해준다. (역자 - 하위공간들 정보에 모델이, 멀티 헤드라서, 동시 억세스할 수 있다.) 싱글 어텐션 헤드에선 평균을 내는 것이 (이러한 부분을) 억제한다.
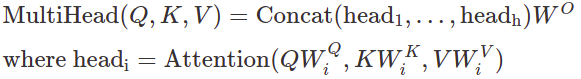
여기서 투영(projections)은 파라미터 행렬(parameter matrices)이다.
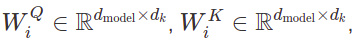

여기서는 h=8 병행 어텐션 레이어(parallel attention layers) 또는 헤드(heads)를 사용한다.
이들 각각에서

각 헤드의 줄어든 dimension 때문에, 총 연산 비용(total computational cost)는 전체 차원수를 가진 싱글-헤드 어텐션(single-head attention)과 비슷하다.
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"모델 사이즈와 헤드의 개수를 받는다"
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"그림 2 구현"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) d_model => h x d_k 로부터의 배치에서 이뤄지는 모든 선형 투영(linear projections)
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) 배치에 있는 모든 projected vectors에 어텐션 적용
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3) view를 사용해서 연결하고, 마지막 linear에 적용
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
이 모델에서의 어텐션의 응용 (applications of Attention in our model)
트랜스포머는 세 종류의 다른 방법으로 멀티-헤드 어텐션을 사용한다: 1) "인코더-디코더 어텐션(encoder-decoder attention) 레이어에서, 질의(queries)는 이전의 디코더 레이어로부터 온다, 그리고 memory 키(keys)와 밸류(values)은 인코더의 아웃풋에서 온다. 이는 디코더 내부의 모든 위치를, 입력 시퀀스(input sequence) 내부의 모든 위치들(positions)에 attend over하려고 허용 해준다.
이는 시퀀스-투-시퀀스 모델(cite)에서의 보편적인 인코더-디코더 어텐션 매커니즘을 모방했다.
2) 인코더는 셀프-어텐션 레이어를 갖고 있다. 셀프-어텐션 레이어에서 모든 키(keys), 밸류(values)와 질의(queries)는 같은 장소에서 온다, 여기서는 인코더에서 이전 레이어의 아웃풋이다. 인코더의 각 포지션은, 인코더의 이전 레이어의 모든 위치(all positions)에 attend 할 수 있다.
3) 비슷하게, 디코더의 셀프-어텐션 레이어는, 최대로는, 디코어의 모든 위치를 attend하도록 디코더의 각 포지션을 허용한다. 디코어데서 leftward 정보의 흐름을 prevent하는 것이, auto-regressive 특성을 보존하기 위해서 필요하다.
우리는 이러한 부분을, 소프트맥스(softmax) 인풋 내부의 연결되면 안되는 부분들(illegal connections, 역자 주:논문에서는 leftward information flow를 illegal connection이라고 규정)에 해당하는 모든 값들을 음의 무한대(−∞)으로 마스크 하고(masking out), 스케일된 내적 어텐션(scaled dot-product attention)의 내부에 적용해 보았다.
포인트-와이즈 피드-포워드 네트워크 (Point-wise Feed-Forward Networks)
어텐션 서브-레이어(attention sub-layers)에 추가해서, 인코더와 디코더 내부의 각 레이어는 완전 연결 피드-포워드 네트워크(fully connected feed-forward network) - 개별적이고 동일하게 각 포지션에 적용되는 - 를 갖고 있다. 이는 그 사이에 하나의 ReLU 활성함수가 적용된, 두 개의 선형 변환(linear transformations)으로 이루어져 있다.
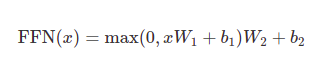
선형 변환이 다른 위치들(different positions)을 동일하게 지날 때, 레이어마다 다른 파라미터들을 사용한다. 다른 방식으로 말하면 커널 크기(kernel size)가 1인 두 개의 컨볼루션(convolutions)로 볼 수 있다. 인풋과 아웃풋의 차원수는 $d_{model}=512$, 그리고 내부-레이어(inner-layer)의 차원수는 $d_{ff}=2048$이다.
class PositionwiseFeedForward(nn.Module):
"FFN 공식 구현"
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
임베딩과 소프트맥스
다른 시퀀스 transduction 모델(sequence transduction models)과 비슷하게, 인풋 토큰과 아웃풋 토큰들을 dmodel의 차원을 가진 벡터들로 바꾸기 위해 임베딩을 학습한다. 보편적인 선형 변환(learned linear transformation)과 소프트맥스 함수(softmax function)도, 디코더의 아웃풋(decoder output)을 다음-토큰의 확률(next-token probabilities)으로 바꾸는데에 사용한다. 여기 모델에서, 두 임베딩 레이어와 pre-softmax linear transformation간에는 동일한 weight matrix를 공유한다. ((cite)와 비슷하다) 임베딩 레이어에서, 이 weights는 $\sqrt {
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
포지셔널 인코딩 (Positional Encoding)
모델이 순환이 없고(no recurrence) 컨볼루션도 없으므로(no convolution), 모델이 시퀀스의 순서를 사용하도록 하게 하려면, 시퀀스의 토큰들의 상대적(relative)이거나 또는 절대적인 위치(absolute position)에 대한 어떤 정보를 넣어줘야 한다. 인코더와 디코더 스택의 하단에 있는 입력 임베딩에 "포지셔널 인코딩(positional encodings, 위치 인코딩)"을 추가한다. 포지셔널 인코딩은 임베딩처럼 dmodel과 같은 차원을 갖고 있기에, 두 개를 합할 수 있다.
포지셔널 인코딩에는, 학습시키거나 고정할 수 있는 많은 선택들이 있다, (cite)
여기서는 다른 빈도수(different frequencies)를 가진 사인과 코사인 함수를 사용한다:
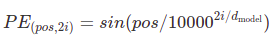
포지셔널 인코딩의 각 차원은 sinusoid에 대응한다. 주파수(wavelengths)는 $ $기하학적인 변화를 형성한다. 모델로 하여금 상대적인 위치에 의한 어텐션을, 이 함수가 쉽게 배우게끔 할 수 있을거라 가정하고 이 함수를 선택했다. (어떤 offset $k$에 대해, $PE_{pos+k}$는 $PE_{pos}$의 선형 함수로 표현될 수 있으므로)
추가적으로, 임베딩의 합들(sums of the embeddings), 그리고 인코더와 디코더 스택 양쪽에 있는 포지셔널 인코딩에 드롭아웃(dropout)을 적용했다. 베이스 모델에서는, $P_{drop}=0.1$을 사용했다.
class PositionalEncoding(nn.Module):
"PE 함수 구현"
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# 로그 스페이스에서 포지셔널 인코딩을 한 번 계산
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)],
requires_grad=False)
return self.dropout(x)하단의 포지셔널 인코딩은 위치에 기반한 사인파(sine wave) 안에 추가될 것입니다. 웨이브(wave)의 주파수(frequency)와 오프셋(offset)은 차원마다 다릅니다.
plt.figure(figsize=(15, 5))
pe = PositionalEncoding(20, 0)
y = pe.forward(Variable(torch.zeros(1, 100, 20)))
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.legend(["dim %d"%p for p in [4,5,6,7]])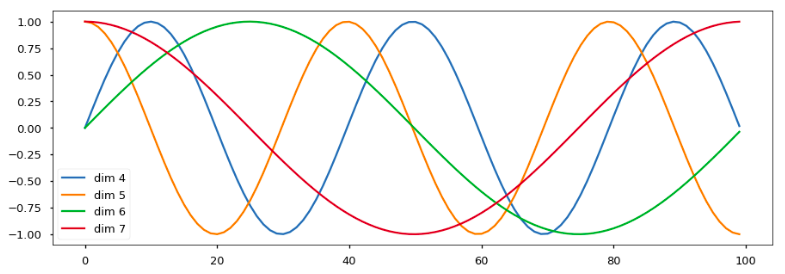
대신 학습된 포지셔널 임베딩 (cite)을 사용해서 실험했고, 두 개의 버전(사인과 코사인)이 거의 동일한 결과를 내놓은 걸 발견했다. sinusoidal version을 선택했는데, 모델이 학습할 때 마주친 것들보다 시퀀스 길이를 더 길게 외삽(extra-polate) 할 수도 있기 때문이다.
전체 모델
여기서 하이퍼파라미터를 받고, 전체 모델을 생성하는 함수를 정의합니다.
def make_model(src_vocab, tgt_vocab, N=6,
d_model=512, d_ff=2048, h=8, dropout=0.1):
"헬퍼: 하이퍼파라미터들로부터 모델을 구축한다"
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn),
c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab))
# 그들 코드(논문 저자들)에서 중요한 부분
# 파라미터는 Glorot / fan_avg.로 초기화한다
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform(p)
return model# 작은 예시 모델
tmp_model = make_model(10, 10, 2)
학습
이 섹션에서는 모델의 학습 방식을 설명한다.
막간을 이용해서 표준적인 인코더 디코더 모델을 트레이닝하는데에 필요한 툴들을 소개하겠습니다. 첫번째로 트레이닝을 위한, 소스와 타겟 문장들을 담고 있는 배치 오브젝트(batch object)를 정의하고 마스크를 만듭니다.
배치들과 마스크 (Batches and Masking)
class Batch:
"학습하는 동안 마스크와 데이터의 배치를 들고 있는 오브젝트"
def __init__(self, src, trg=None, pad=0):
self.src = src
self.src_mask = (src != pad).unsqueeze(-2)
if trg is not None:
self.trg = trg[:, :-1]
self.trg_y = trg[:, 1:]
self.trg_mask = \
self.make_std_mask(self.trg, pad)
self.ntokens = (self.trg_y != pad).data.sum()
@staticmethod
def make_std_mask(tgt, pad):
"패딩을 숨기고 이후 단어들을 위한 마스크를 생성"
tgt_mask = (tgt != pad).unsqueeze(-2)
tgt_mask = tgt_mask & Variable(
subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data))
return tgt_mask다음으로 트레이닝과 손실(loss) 트래킹을 할 수 있는 채점 함수(scoring function)를 만듭니다. 손실을 계산(loss compute function)하고 파라미터 업데이트(parameter updates)도 조정하는 함수를 전달합니다.
트레이닝 루프 (Training Loop)
def run_epoch(data_iter, model, loss_compute):
"표준 학습과 로그 남기기 함수"
start = time.time()
total_tokens = 0
total_loss = 0
tokens = 0
for i, batch in enumerate(data_iter):
out = model.forward(batch.src, batch.trg,
batch.src_mask, batch.trg_mask)
loss = loss_compute(out, batch.trg_y, batch.ntokens)
total_loss += loss
total_tokens += batch.ntokens
tokens += batch.ntokens
if i % 50 == 1:
elapsed = time.time() - start
print("Epoch Step: %d Loss: %f Tokens per Sec: %f" %
(i, loss / batch.ntokens, tokens / elapsed))
start = time.time()
tokens = 0
return total_loss / total_tokens
트레이닝 데이터와 배치 만들기 (Training Data and Batching)
4.5백만개의 문장 페어로 구성된, 표준 WMT 2014 영어-독일어 데이터셋을 트레이닝했다. 37000개 토큰들에 대한 소스-타겟 어휘를 가진 이 문장들은 byte-pair encoding (BPE)를 사용해서 인코딩되었다. 영어-불어를 위해, 훨씬 더 큰 36M 문장들로 이루어진 WMT 2014 영어-불어 데이터셋과 32000 워드-피스 (word-piece) 어휘로 분리한 토큰들을 사용했다.
문장 페어는 대략적인 시퀀스 길이로 함께 배치되었다. 각 트레이닝 배치는 대략 25000 소스 토큰과 25000 타겟 토큰들을 가진 문장 페어 세트를 갖고 있다.
배치를 만들기 위해서 토치 텍스트(torch text)를 사용할 것입니다. 세부적인 내용은 아래에 논의되어 있습니다. 여기 torchtext 함수에서 배치를 만드는 건, 배치 사이즈를 패딩(padded)해서 최대 배치 사이즈가 임계값을 넘지 않도록 합니다. (8개의 GPU가 있다면 25000)
global max_src_in_batch, max_tgt_in_batch
def batch_size_fn(new, count, sofar):
"큰 배치를 유지하고 토큰 + 패딩의 총합을 계산한다"
global max_src_in_batch, max_tgt_in_batch
if count == 1:
max_src_in_batch = 0
max_tgt_in_batch = 0
max_src_in_batch = max(max_src_in_batch, len(new.src))
max_tgt_in_batch = max(max_tgt_in_batch, len(new.trg) + 2)
src_elements = count * max_src_in_batch
tgt_elements = count * max_tgt_in_batch
return max(src_elements, tgt_elements)
하드웨어와 스케쥴
8개의 엔비디아 P100 GPU가 달린 컴퓨터로 트레이닝을 했다. 베이스 모델에 쓰인 하이퍼파라미터들은 논문에 적혀져 있으며, 각 트레이닝 스텝은 0.4초가 걸렸다. 베이스 모델은 총 10만 스텝 또는 12시간동안 트레이닝시켰다. 큰 모델은 30만 스텝 (3.5 일)을 트레이닝 했다.
옵티마이저
$\beta1=0.9$와 $\beta2=0.98$, 그리고 $\epsilon=10^{-9}$의 아담 옵티마이저(cite)를 사용했다. 트레이닝을 하는 동안 러닝 레이트(learning rate)를 하단의 공식을 따라 다양하게 했다.
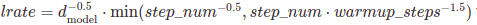
이는 첫 웜업 스텝(warmup steps, 초기 학습률을 작게 해서 천천히 트레이닝 시키는 것), 트레이닝 스텝 동안 러닝 레이트를 선형으로 증가시키는 것에 해당하며, 그 이후에는 스텝 개수의 역 제곱근(inverse square root)에 비례해서 줄여나간다. 우리는 웜업 스텝으로 4000을 사용했다.
노트 : 이 부분은 매우 중요합니다. 모델을 이렇게 설정하고 트레이닝하는 게 필요합니다.
class NoamOpt:
"rate를 구현하는 옵티마이저 래퍼(optim wrapper)"
def __init__(self, model_size, factor, warmup, optimizer):
self.optimizer = optimizer
self._step = 0
self.warmup = warmup
self.factor = factor
self.model_size = model_size
self._rate = 0
def step(self):
"파라미터와 레이트 업데이트"
self._step += 1
rate = self.rate()
for p in self.optimizer.param_groups:
p['lr'] = rate
self._rate = rate
self.optimizer.step()
def rate(self, step = None):
"위의 'lrate' 구현"
if step is None:
step = self._step
return self.factor * \
(self.model_size ** (-0.5) *
min(step ** (-0.5), step * self.warmup ** (-1.5)))
def get_std_opt(model):
return NoamOpt(model.src_embed[0].d_model, 2, 4000,
torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9))서로 다른 모델 사이즈와 최적화(optimiztion) 하이퍼 파라미터(hyperparameters)를 (적용한) 이 모델의 커브 (형태) 예시입니다.
# lrate 하이퍼파라미터의 세가지 세팅.
opts = [NoamOpt(512, 1, 4000, None),
NoamOpt(512, 1, 8000, None),
NoamOpt(256, 1, 4000, None)]
plt.plot(np.arange(1, 20000), [[opt.rate(i) for opt in opts] for i in range(1, 20000)])
plt.legend(["512:4000", "512:8000", "256:4000"])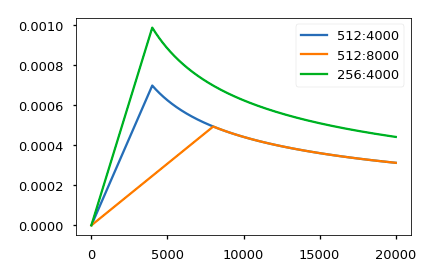
정규화 (Regularization)
레이블 스무딩
트레이닝을 하는 동안, $\epsilon_{ls}=0.1$ (cite) 값의 레이블 스무딩을 사용했다. 모델이 학습하는 걸 더 불확실하게 만들기에 PPL(perplexity)를 손상시키지만, 정확도와 BLEU 스코어를 향상시킨다.
KL 다이버전스 로스(KL Divergence loss)를 사용해서 레이블 스무딩을 적용했습니다. 원-핫 타겟 분포(one-hot target distribution)를 사용하는 대신, 올바른 단어의 확신도(confidence)를 가지는 분포로 만들었고, 나머지 스무딩 질량(smoothing mass)은 어휘 전체에 분포되도록 했습니다.
class LabelSmoothing(nn.Module):
"레이블 스무딩 구현"
def __init__(self, size, padding_idx, smoothing=0.0):
super(LabelSmoothing, self).__init__()
self.criterion = nn.KLDivLoss(size_average=False)
self.padding_idx = padding_idx
self.confidence = 1.0 - smoothing
self.smoothing = smoothing
self.size = size
self.true_dist = None
def forward(self, x, target):
assert x.size(1) == self.size
true_dist = x.data.clone()
true_dist.fill_(self.smoothing / (self.size - 2))
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence)
true_dist[:, self.padding_idx] = 0
mask = torch.nonzero(target.data == self.padding_idx)
if mask.dim() > 0:
true_dist.index_fill_(0, mask.squeeze(), 0.0)
self.true_dist = true_dist
return self.criterion(x, Variable(true_dist, requires_grad=False))여기서 질량(mass)이 확신도(confidence)에 기반하여 단어들에 분포되는 예시를 볼 수 있습니다.
# 레이블 스무딩 예시
crit = LabelSmoothing(5, 0, 0.4)
predict = torch.FloatTensor([[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0]])
v = crit(Variable(predict.log()),
Variable(torch.LongTensor([2, 1, 0])))
# 시스템에 의해 예측된 타겟 분포 보여주기
plt.imshow(crit.true_dist)
만약 모델이 주어진 선택에 대해서 매우 확신하기 시작한다면, 레이블 스무딩은 사실 모델에 패널티를 주기 시작합니다.
crit = LabelSmoothing(5, 0, 0.1)
def loss(x):
d = x + 3 * 1
predict = torch.FloatTensor([[0, x / d, 1 / d, 1 / d, 1 / d],
])
#print(predict)
return crit(Variable(predict.log()),
Variable(torch.LongTensor([1]))).data[0]
plt.plot(np.arange(1, 100), [loss(x) for x in range(1, 100)])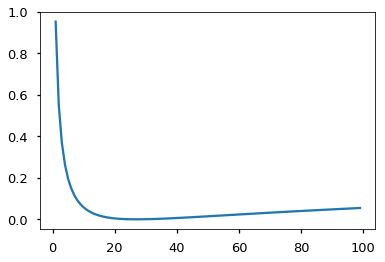
첫번째 예시
간단한 복사 태스크를 시도해보는 것으로 시작해봅시다. 작은 어휘(vocabulary)로부터 온 인풋 심볼들의 랜덤한 세트가 주어져 있고, 목표는 같은 심볼들을 다시 생성해내는 것입니다.
합성된 데이터
def data_gen(V, batch, nbatches):
"src-tgt 복사 태스크를 위해 랜덤 데이터 생성하기"
for i in range(nbatches):
data = torch.from_numpy(np.random.randint(1, V, size=(batch, 10)))
data[:, 0] = 1
src = Variable(data, requires_grad=False)
tgt = Variable(data, requires_grad=False)
yield Batch(src, tgt, 0)손실 연산하기
class SimpleLossCompute:
"간단한 손실 계산과 트레이닝 함수"
def __init__(self, generator, criterion, opt=None):
self.generator = generator
self.criterion = criterion
self.opt = opt
def __call__(self, x, y, norm):
x = self.generator(x)
loss = self.criterion(x.contiguous().view(-1, x.size(-1)),
y.contiguous().view(-1)) / norm
loss.backward()
if self.opt is not None:
self.opt.step()
self.opt.optimizer.zero_grad()
return loss.data[0] * norm그리디 디코딩 (탐욕 디코딩, Greedy Decoding)
# 간단한 복사 태스크 학습하기
V = 11
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
model = make_model(V, V, N=2)
model_opt = NoamOpt(model.src_embed[0].d_model, 1, 400,
torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9))
for epoch in range(10):
model.train()
run_epoch(data_gen(V, 30, 20), model,
SimpleLossCompute(model.generator, criterion, model_opt))
model.eval()
print(run_epoch(data_gen(V, 30, 5), model,
SimpleLossCompute(model.generator, criterion, None)))Epoch Step: 1 Loss: 3.023465 Tokens per Sec: 403.074173
Epoch Step: 1 Loss: 1.920030 Tokens per Sec: 641.689380
1.9274832487106324
Epoch Step: 1 Loss: 1.940011 Tokens per Sec: 432.003378
Epoch Step: 1 Loss: 1.699767 Tokens per Sec: 641.979665
1.657595729827881
Epoch Step: 1 Loss: 1.860276 Tokens per Sec: 433.320240
Epoch Step: 1 Loss: 1.546011 Tokens per Sec: 640.537198
1.4888023376464843
Epoch Step: 1 Loss: 1.682198 Tokens per Sec: 432.092305
Epoch Step: 1 Loss: 1.313169 Tokens per Sec: 639.441857
1.3485562801361084
Epoch Step: 1 Loss: 1.278768 Tokens per Sec: 433.568756
Epoch Step: 1 Loss: 1.062384 Tokens per Sec: 642.542067
0.9853351473808288
Epoch Step: 1 Loss: 1.269471 Tokens per Sec: 433.388727
Epoch Step: 1 Loss: 0.590709 Tokens per Sec: 642.862135
0.5686767101287842
Epoch Step: 1 Loss: 0.997076 Tokens per Sec: 433.009746
Epoch Step: 1 Loss: 0.343118 Tokens per Sec: 642.288427
0.34273059368133546
Epoch Step: 1 Loss: 0.459483 Tokens per Sec: 434.594030
Epoch Step: 1 Loss: 0.290385 Tokens per Sec: 642.519464
0.2612409472465515
Epoch Step: 1 Loss: 1.031042 Tokens per Sec: 434.557008
Epoch Step: 1 Loss: 0.437069 Tokens per Sec: 643.630322
0.4323212027549744
Epoch Step: 1 Loss: 0.617165 Tokens per Sec: 436.652626
Epoch Step: 1 Loss: 0.258793 Tokens per Sec: 644.372296
0.27331129014492034이 코드는 (단순성을 위해서) 그리디 디코딩을 사용해서 번역을 예측합니다.
def greedy_decode(model, src, src_mask, max_len, start_symbol):
memory = model.encode(src, src_mask)
ys = torch.ones(1, 1).fill_(start_symbol).type_as(src.data)
for i in range(max_len-1):
out = model.decode(memory, src_mask,
Variable(ys),
Variable(subsequent_mask(ys.size(1))
.type_as(src.data)))
prob = model.generator(out[:, -1])
_, next_word = torch.max(prob, dim = 1)
next_word = next_word.data[0]
ys = torch.cat([ys,
torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=1)
return ys
model.eval()
src = Variable(torch.LongTensor([[1,2,3,4,5,6,7,8,9,10]]) )
src_mask = Variable(torch.ones(1, 1, 10) )
print(greedy_decode(model, src, src_mask, max_len=10, start_symbol=1)) 1 2 3 4 5 6 7 8 9 10
[torch.LongTensor of size 1x10]
실제 예시
이제 IWSLT 독일어-영어 번역 태스크를 통해, 현실 문제를 생각해봅시다. 이건 논문에 나온 WMT 태스크보다 훨씬 작지만, 전체 시스템을 잘 알려줍니다. 그리고 속도를 정말 빠르게 하는 다중 GPU 프로세싱을 어떻게 사용하는지도 보여주겠습니다.
!pip install torchtext spacy
!python -m spacy download en
!python -m spacy download de
데이터 로딩
토치텍스트(torchtext)와 토큰을 만들기(tokenization) 위한 스페이시(spacy)를 사용해서 데이터를 로드합니다.
# 데이터 로딩
from torchtext import data, datasets
if True:
import spacy
spacy_de = spacy.load('de')
spacy_en = spacy.load('en')
def tokenize_de(text):
return [tok.text for tok in spacy_de.tokenizer(text)]
def tokenize_en(text):
return [tok.text for tok in spacy_en.tokenizer(text)]
BOS_WORD = '<s>'
EOS_WORD = '</s>'
BLANK_WORD = "<blank>"
SRC = data.Field(tokenize=tokenize_de, pad_token=BLANK_WORD)
TGT = data.Field(tokenize=tokenize_en, init_token = BOS_WORD,
eos_token = EOS_WORD, pad_token=BLANK_WORD)
MAX_LEN = 100
train, val, test = datasets.IWSLT.splits(
exts=('.de', '.en'), fields=(SRC, TGT),
filter_pred=lambda x: len(vars(x)['src']) <= MAX_LEN and
len(vars(x)['trg']) <= MAX_LEN)
MIN_FREQ = 2
SRC.build_vocab(train.src, min_freq=MIN_FREQ)
TGT.build_vocab(train.trg, min_freq=MIN_FREQ)배치를 하는 건 속도 처리면에서 큰 문제입니다. 최소한의 패딩으로, 배치가 매우 균일하게 나눠졌으면 좋겠습니다. 이를 위해서 기본 토치텍스트 배치(torchtext batching)를 조금 틀어야 합니다. (최대한으로) 꽉채운 배치를 찾으려 충분한 양의 문장들을 확실히 탐색하기 위해, (토치텍스트의) 기본 배치 과정을 수정해 보았습니다.
이터레이터 (반복자, Iterators)
class MyIterator(data.Iterator):
def create_batches(self):
if self.train:
def pool(d, random_shuffler):
for p in data.batch(d, self.batch_size * 100):
p_batch = data.batch(
sorted(p, key=self.sort_key),
self.batch_size, self.batch_size_fn)
for b in random_shuffler(list(p_batch)):
yield b
self.batches = pool(self.data(), self.random_shuffler)
else:
self.batches = []
for b in data.batch(self.data(), self.batch_size,
self.batch_size_fn):
self.batches.append(sorted(b, key=self.sort_key))
def rebatch(pad_idx, batch):
"우리것과 매치해보기 위해 torchtext의 순서 고정"
src, trg = batch.src.transpose(0, 1), batch.trg.transpose(0, 1)
return Batch(src, trg, pad_idx)
다중 GPU 트레이닝
마지막으로 빠른 트레이닝을 목표로 하기 위해, 다중 GPU를 사용할 것입니다. 이 코드는 다중 GPU 단어 생성을 구현한 것입니다. 트랜스포머에 대한 세부 내용은 아니므로, 너무 깊게 들어가진 않을겁니다. 학습할 때 단어 생성기(word generator)를 청크(chunks)로 나눠서, 많은 다른 GPU들 사이에서 병렬(parallel)로 처리하게 하는 아이디어입니다.
- replicate - 각기 다른 gpu들 위의 분할 모듈
- scatter - 각기 다른 gpu들 위의 분할 배치들
- parallel_apply - 각기 다른 gpus에 모듈을 배치로 적용
- gather - 흩어진 데이터를 하나의 gpu위로 가져옴
- nn.DataParallel - 평가하기(evaluating) 이전에 이들 모두를 호출하는 특수 모듈 래퍼 (a special module wrapper)
# 멀티 gpu에 관심이 없다면 여긴 스킵해도 괜찮다
class MultiGPULossCompute:
"A multi-gpu loss compute and train function."
def __init__(self, generator, criterion, devices, opt=None, chunk_size=5):
# Send out to different gpus.
self.generator = generator
self.criterion = nn.parallel.replicate(criterion,
devices=devices)
self.opt = opt
self.devices = devices
self.chunk_size = chunk_size
def __call__(self, out, targets, normalize):
total = 0.0
generator = nn.parallel.replicate(self.generator,
devices=self.devices)
out_scatter = nn.parallel.scatter(out,
target_gpus=self.devices)
out_grad = [[] for _ in out_scatter]
targets = nn.parallel.scatter(targets,
target_gpus=self.devices)
# 생성 작업을 청크 단위로 나눈다
chunk_size = self.chunk_size
for i in range(0, out_scatter[0].size(1), chunk_size):
# 분포 예측
out_column = [[Variable(o[:, i:i+chunk_size].data,
requires_grad=self.opt is not None)]
for o in out_scatter]
gen = nn.parallel.parallel_apply(generator, out_column)
# 손실(loss) 계산
y = [(g.contiguous().view(-1, g.size(-1)),
t[:, i:i+chunk_size].contiguous().view(-1))
for g, t in zip(gen, targets)]
loss = nn.parallel.parallel_apply(self.criterion, y)
# 손실값(loss)을 합치고 노말라이즈
l = nn.parallel.gather(loss,
target_device=self.devices[0])
l = l.sum()[0] / normalize
total += l.data[0]
# 트랜스포머의 아웃풋으로 손실값(loss)을 백프로파게이션(backprop)
if self.opt is not None:
l.backward()
for j, l in enumerate(loss):
out_grad[j].append(out_column[j][0].grad.data.clone())
# 트랜스포머를 거쳐 모든 손실값(loss)을 백프로파게이션(backprop)
if self.opt is not None:
out_grad = [Variable(torch.cat(og, dim=1)) for og in out_grad]
o1 = out
o2 = nn.parallel.gather(out_grad,
target_device=self.devices[0])
o1.backward(gradient=o2)
self.opt.step()
self.opt.optimizer.zero_grad()
return total * normalize이제 모델을 생성하고, 기준, 옵티마이저, 데이터 이터레이터 그리고 병렬화를 합니다.
# GPU 사용
devices = [0, 1, 2, 3]
if True:
pad_idx = TGT.vocab.stoi["<blank>"]
model = make_model(len(SRC.vocab), len(TGT.vocab), N=6)
model.cuda()
criterion = LabelSmoothing(size=len(TGT.vocab), padding_idx=pad_idx, smoothing=0.1)
criterion.cuda()
BATCH_SIZE = 12000
train_iter = MyIterator(train, batch_size=BATCH_SIZE, device=0,
repeat=False, sort_key=lambda x: (len(x.src), len(x.trg)),
batch_size_fn=batch_size_fn, train=True)
valid_iter = MyIterator(val, batch_size=BATCH_SIZE, device=0,
repeat=False, sort_key=lambda x: (len(x.src), len(x.trg)),
batch_size_fn=batch_size_fn, train=False)
model_par = nn.DataParallel(model, device_ids=devices)
None이제 모델을 학습합니다. 약간의 웜업 스텝이 있겠지만, 다른 모든것들은 기본 파라미터들을 사용합니다. 4개의 테슬라 V100를 가진 AWS p3.8xlarge에서, 12,000의 배치사이즈로 초당 ~27,000 토큰까지 실행시킵니다.
시스템 학습시키기
!wget https://s3.amazonaws.com/opennmt-models/iwslt.ptif False:
model_opt = NoamOpt(model.src_embed[0].d_model, 1, 2000,
torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9))
for epoch in range(10):
model_par.train()
run_epoch((rebatch(pad_idx, b) for b in train_iter),
model_par,
MultiGPULossCompute(model.generator, criterion,
devices=devices, opt=model_opt))
model_par.eval()
loss = run_epoch((rebatch(pad_idx, b) for b in valid_iter),
model_par,
MultiGPULossCompute(model.generator, criterion,
devices=devices, opt=None))
print(loss)
else:
model = torch.load("iwslt.pt")한 번 학습이 되면 모델이 번역본 세트 하나를 생성하게 디코딩(decode) 할 수 있습니다. (once trained we can decode the model to produce a set of translations) 여기 검증 세트에 있는 첫번째 문장을 번역해봅시다. 이 데이터셋은 꽤 작아서 탐욕 탐색 (greedy search)으로 번역을 해도 상당히 정확합니다.
for i, batch in enumerate(valid_iter):
src = batch.src.transpose(0, 1)[:1]
src_mask = (src != SRC.vocab.stoi["<blank>"]).unsqueeze(-2)
out = greedy_decode(model, src, src_mask,
max_len=60, start_symbol=TGT.vocab.stoi["<s>"])
print("Translation:", end="\t")
for i in range(1, out.size(1)):
sym = TGT.vocab.itos[out[0, i]]
if sym == "</s>": break
print(sym, end =" ")
print()
print("Target:", end="\t")
for i in range(1, batch.trg.size(0)):
sym = TGT.vocab.itos[batch.trg.data[i, 0]]
if sym == "</s>": break
print(sym, end =" ")
print()
breakTranslation: <unk> <unk> . In my language , that means , thank you very much .
Gold: <unk> <unk> . It means in my language , thank you very much .
추가적인 요소들 : BPE(Byte Pair Encoding, 바이트 페어 인코딩), 탐색 (Search), 평균내기 (Averaging)
이제 트랜스포머 모델 자체에 대한 대부분의 내용을 알았습니다. 직접적으로 언급하지 않은 네 가지의 관점이 있습니다. 이 추가적인 피쳐들은 OpenNMT-py에서도 적용해두었습니다.
1) BPE / 워드-피스 (Word-piece): 라이브러리를 써서 데이터를 서브워드 유닛들로 나누는 첫번째 전처리 작업을 할 수 있습니다. 리코 센리치(Rico Sennrich)의 subword-nmt 구현을 보세요. 이 모델들은 트레이닝 데이터를 아래처럼 바꿉니다:
▁Die ▁Protokoll datei ▁kann ▁ heimlich ▁per ▁E - Mail ▁oder ▁FTP ▁an ▁einen ▁bestimmte n ▁Empfänger ▁gesendet ▁werden .
2) 임베딩 공유하기 (Shared Embeddings): 공유된 어휘집(shared vocabulary)에 BPE를 쓸 때, 소스(문장)와 타겟(문장), 생성기(generator)간에 같은 가중치 벡터들을 공유할 수 있습니다. 세부적인건 (cite)를 참고해주세요. 이를 간단하게 아래처럼 모델에 추가합니다:
if False:
model.src_embed[0].lut.weight = model.tgt_embeddings[0].lut.weight
model.generator.lut.weight = model.tgt_embed[0].lut.weight3) 빔 서치 (Beam Search): 여기서 다루기엔 좀 복잡합니다. 파이토치 버전의 OpenNMT-py를 봐 주세요 (역자주: 기존의 링크가 깨어져서, 새로 beam_search.py를 찾아서 링크를 걸었습니다.)
4) 모델 평균내기 (Model Averaging): 논문에서는 앙상블 표과를 내기 위해 마지막 k개의 체크포인트들을 평균냈습니다. 모델이 많다면 이후에 이를 할 수 있습니다.
def average(model, models):
"모델들 평균낸 값을 모델에 넣음"
for ps in zip(*[m.params() for m in [model] + models]):
p[0].copy_(torch.sum(*ps[1:]) / len(ps[1:]))
결과물
WMT 2014 영어-독일어 번역 태스크에서, 대형 트랜스포머 모델 (테이블2의 Transformer (big))은 이전에 발표된 최고의 모델들 (앙상블 포함)을, 28.4의 새로운 SOTA BLEU 스코어를 기록하면서, 2.0 BLEU 이상 뛰어넘었다. 모델의 구성은 테이블 3의 최하단 라인에 리스트되어 있다. 8개의 P100 GPU들로 3.5일간 트레이닝을 했다. 기본 모델조차, 경쟁 모델 학습 비용의 일부만으로, 이전에 발표된 모든 모델들과 앙상블들을 뛰어넘었다.
WMT 2014 영어-에서-불어로 번역하는 태스크(English-to-French translation task)에서, 대형 모델은 이전 SOTA 모델의 1/4 이하의 학습비용만으로, 41.0의 BLEU 스코어를 기록했다. 이전에 발표된 모든 싱글 모델들을 뛰어넘는 수치이다. 영어-에서-불어 번역을 위한 대형 트랜스포머 (The Transformer (big)) 모델은 0.3 대신에 dropout rate $P_{drop} = 0.1$로 트레이닝되었다.
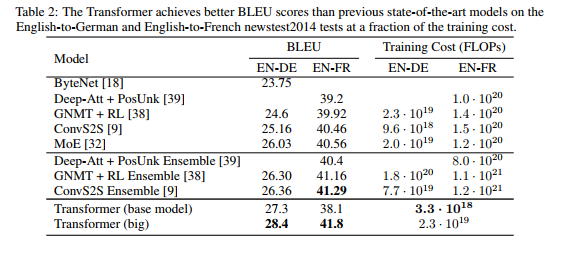
여기서 쓴 코드는 기본 모델의 버전입니다. 이 시스템의 완전히 트레이닝된 버전은 여기서 볼 수 있습니다. (예시 모델)
마지막 섹션에 있는 추가 확장판들로, OpenNMT-py 복제판은 영어-독일어 WMT (데이터셋)에서 26.9 (BLEU score)를 받습니다. 여기에 재 구현을 위한 파라미터들을 로드했습니다.
!wget https://s3.amazonaws.com/opennmt-models/en-de-model.ptmodel, SRC, TGT = torch.load("en-de-model.pt")model.eval()
sent = "▁The ▁log ▁file ▁can ▁be ▁sent ▁secret ly ▁with ▁email ▁or ▁FTP ▁to ▁a ▁specified ▁receiver".split()
src = torch.LongTensor([[SRC.stoi[w] for w in sent]])
src = Variable(src)
src_mask = (src != SRC.stoi["<blank>"]).unsqueeze(-2)
out = greedy_decode(model, src, src_mask,
max_len=60, start_symbol=TGT.stoi["<s>"])
print("Translation:", end="\t")
trans = "<s> "
for i in range(1, out.size(1)):
sym = TGT.itos[out[0, i]]
if sym == "</s>": break
trans += sym + " "
print(trans)Translation: <s> ▁Die ▁Protokoll datei ▁kann ▁ heimlich ▁per ▁E - Mail ▁oder ▁FTP ▁an ▁einen ▁bestimmte n ▁Empfänger ▁gesendet ▁werden .
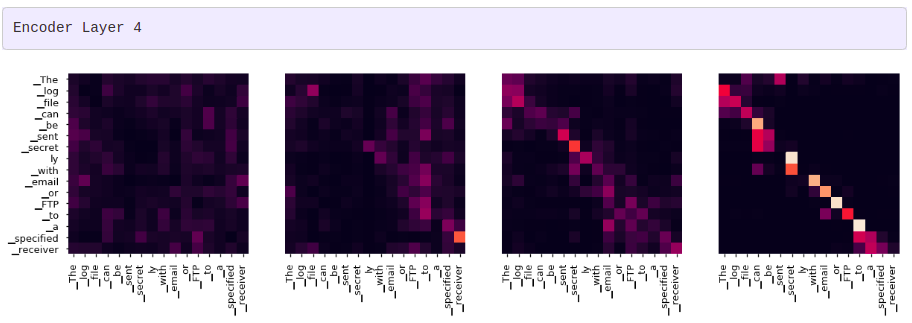
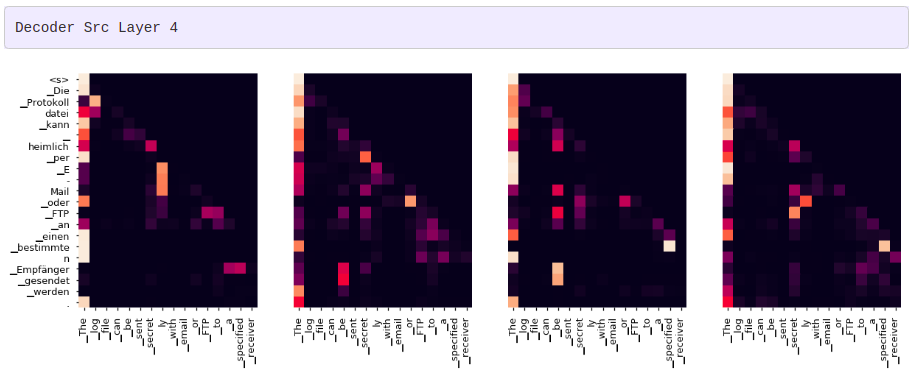
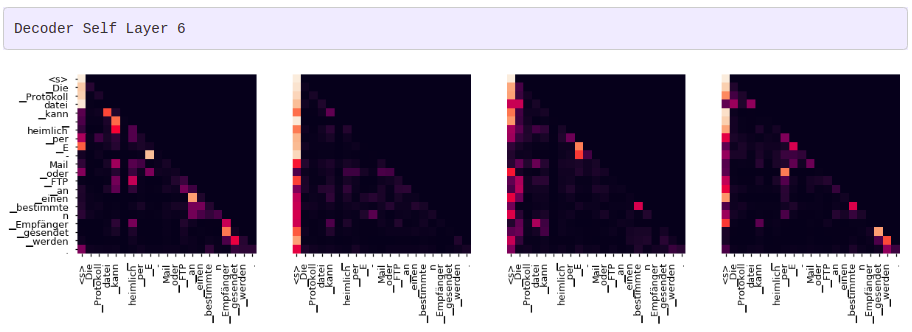
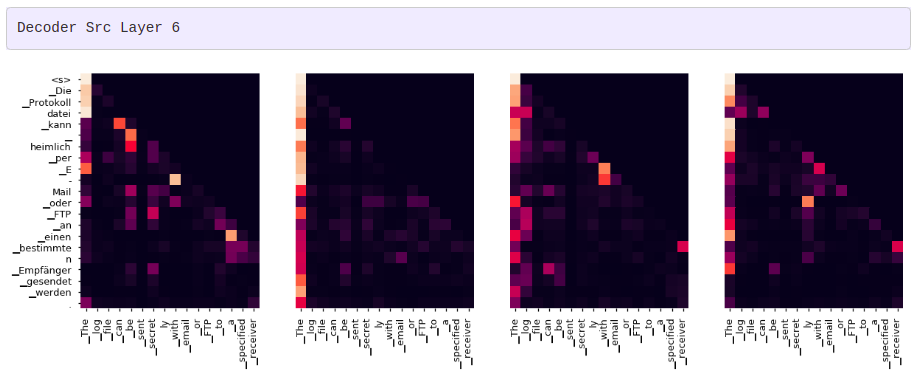
어텐션 시각화
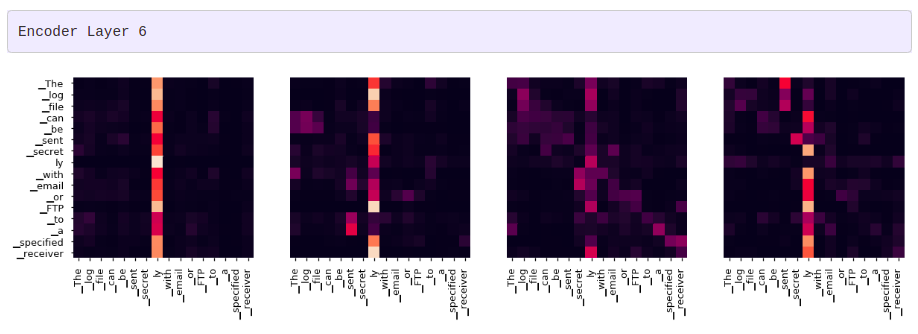
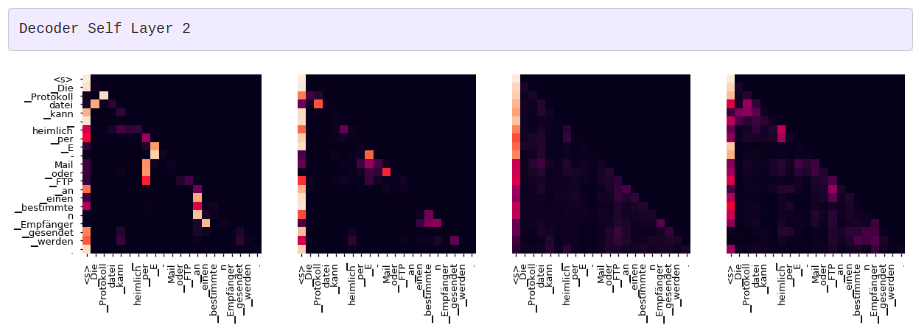
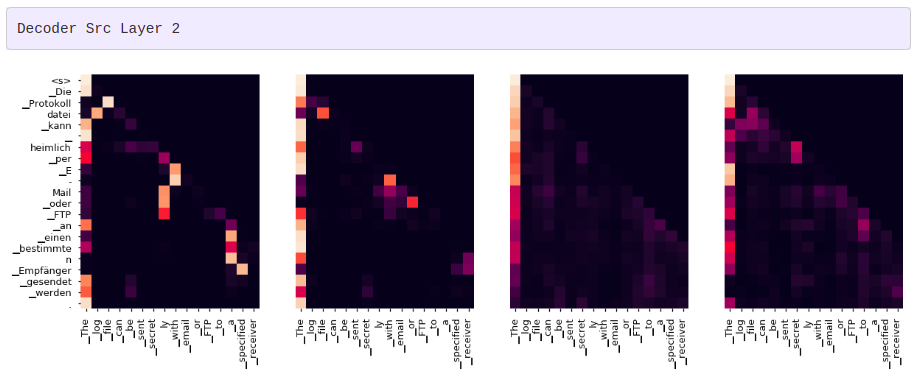
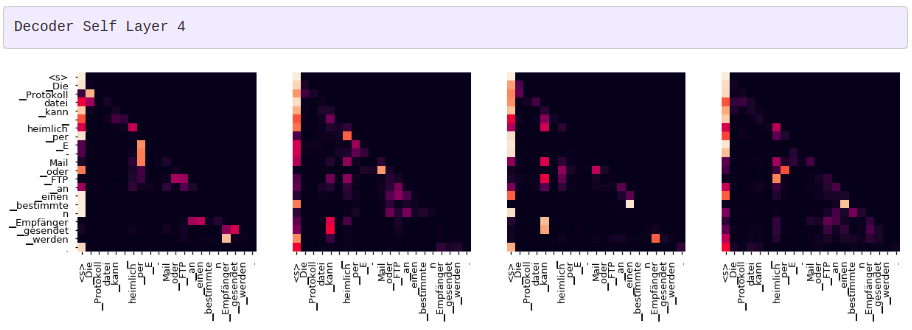
그리디 디코더 (greedy decoder)를 사용해 번역을 하더라도 꽤 괜찮아 보입니다. 더 나아가 어텐션의 각 레이어마다 무슨 일이 일어나는지를 시각화할 수 있습니다.
tgt_sent = trans.split()
def draw(data, x, y, ax):
seaborn.heatmap(data,
xticklabels=x, square=True, yticklabels=y, vmin=0.0, vmax=1.0,
cbar=False, ax=ax)
for layer in range(1, 6, 2):
fig, axs = plt.subplots(1,4, figsize=(20, 10))
print("Encoder Layer", layer+1)
for h in range(4):
draw(model.encoder.layers[layer].self_attn.attn[0, h].data,
sent, sent if h ==0 else [], ax=axs[h])
plt.show()
for layer in range(1, 6, 2):
fig, axs = plt.subplots(1,4, figsize=(20, 10))
print("Decoder Self Layer", layer+1)
for h in range(4):
draw(model.decoder.layers[layer].self_attn.attn[0, h].data[:len(tgt_sent), :len(tgt_sent)],
tgt_sent, tgt_sent if h ==0 else [], ax=axs[h])
plt.show()
print("Decoder Src Layer", layer+1)
fig, axs = plt.subplots(1,4, figsize=(20, 10))
for h in range(4):
draw(model.decoder.layers[layer].self_attn.attn[0, h].data[:len(tgt_sent), :len(sent)],
sent, tgt_sent if h ==0 else [], ax=axs[h])
plt.show()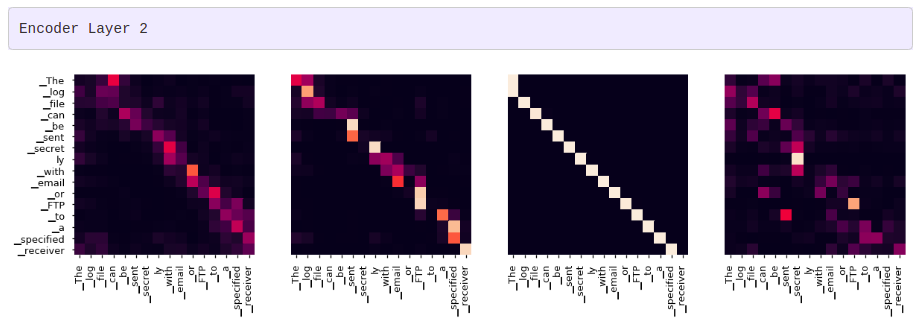
결론
이후의 연구에 이 코드가 유용하길 바랍니다. 만약 (이 코드로 무언가를 해보다가) 어떤 이슈가 생겼다면 알려주세요. 혹시 이 코드가 도움이 되었다면, 우리의 다른 OpenNMT 툴들도 확인해주세요.
@inproceedings{opennmt,
저자 = {Guillaume Klein and
Yoon Kim and
Yuntian Deng and
Jean Senellart and
Alexander M. Rush},
타이틀 = {OpenNMT: Open-Source Toolkit for Neural Machine Translation},
booktitle = {Proc. ACL},
year = {2017},
url = {https://doi.org/10.18653/v1/P17-4012},
doi = {10.18653/v1/P17-4012}
}
Cheers, srush
오탈자나 기타 오번역 부분이 있다면, 이 포스트에 리플로 달아주세요 :)
감사합니다.
- Soohyun
'Machine Learning > Natural Language Processing' 카테고리의 다른 글
| A Survey of NLP-Related Crowdsourcing HITs: what works and what does not (0) | 2021.11.28 |
|---|
