
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- #링글후기
- 영어공부
- 영어시험
- 영어로전세계와소통하기
- 링글
- 스몰토크
- 영어공부법
- 화상영어
- 링글경험담
- 장어랑고기같이
- 오피스밋업
- #nlp
- #체험수업
- 영어회화
- #링글
- 해외취업컨퍼런스
- 뉴노멀챌린지
- 소통챌린지
- 총각네장어
- #영어발음교정
- #직장인영어
- 링글커리어
- CommunicateWiththeWorld
- #영어공부
- #Ringle
- 링글리뷰
- 둔촌역장어
- 성내동장어
- Ringle
- 강동구장어맛집
- Today
- Total
Soohyun’s Machine-learning
[NLP][GPT3] Language Models are Few-Shot Learners 본문

- GPT2의 계승 모델로, GPT3라고 부른다
- GPT는 Generative Pre-Training의 약자
(GPT1 논문 제목이 Improving Language Understanding by Generative Pre-Training)
- input : N개의 단어 sequence
- output : N+1번째의 단어
- GPT2 사이즈 업 + Unsupervised pre-training (like NLG) + Sparse Attention + No fine-tuning
Alternating dense and Locally banded sparse attention
- (a) Transaformer처럼 앞쪽의 전부를 보면 연산량이 많으므로, (b)나 (c)처럼 제한된 개수의 input token에만 attention을 한다
- 긴 길이를 더 잘 attention 한다 (참고로 사용한 seq_length (context window) = 2048)

(task-specific한 fine-tuning을 하지 않음)
- Autoregressive (AR) model (단방향 모델, uni-directional model)
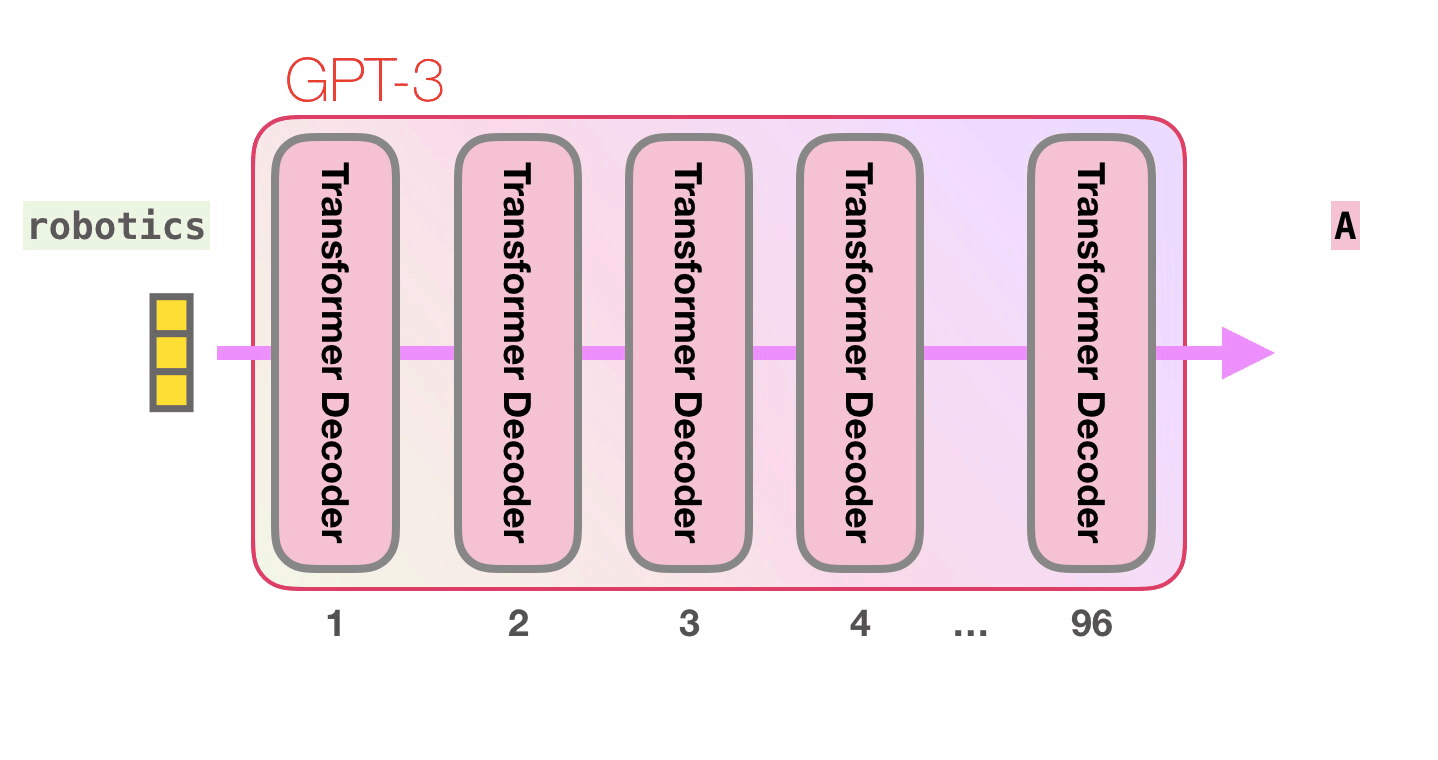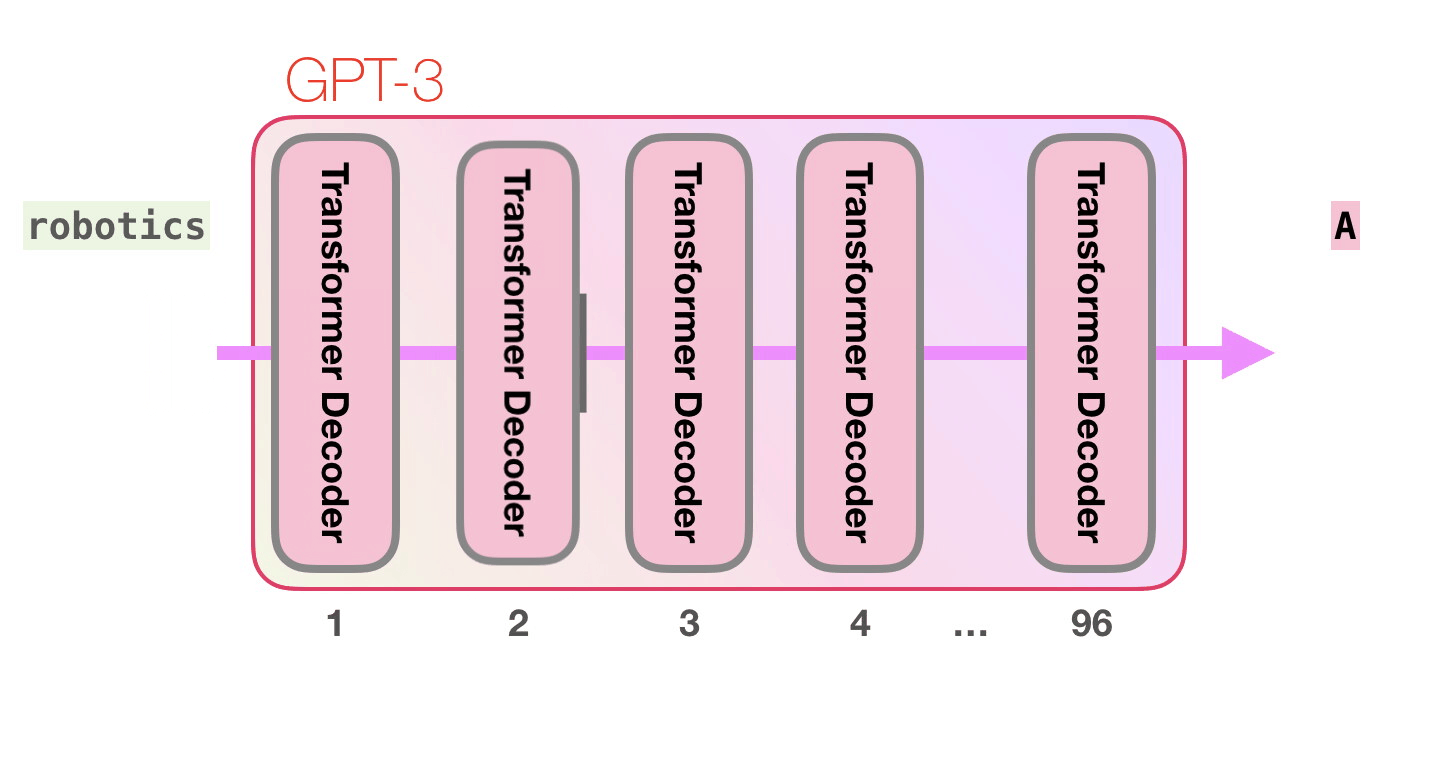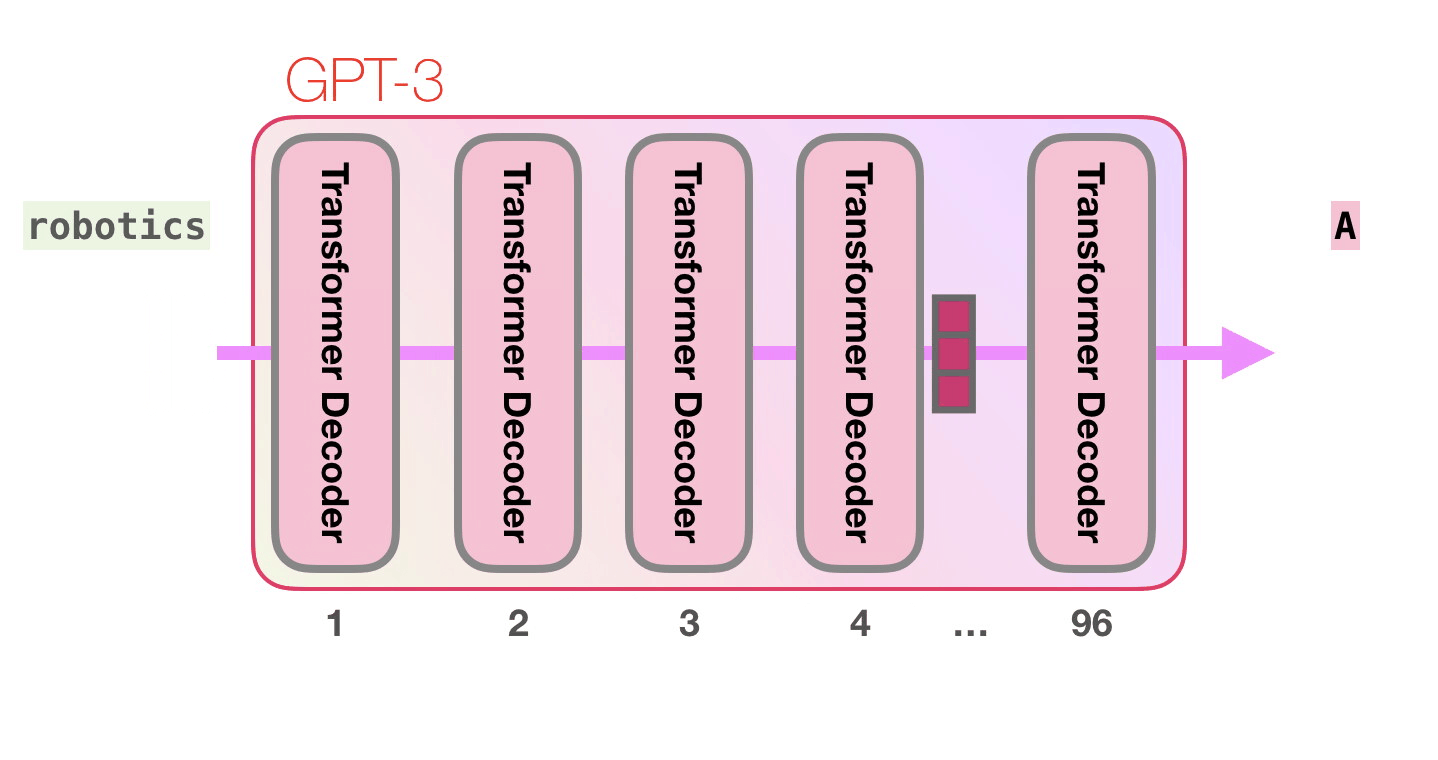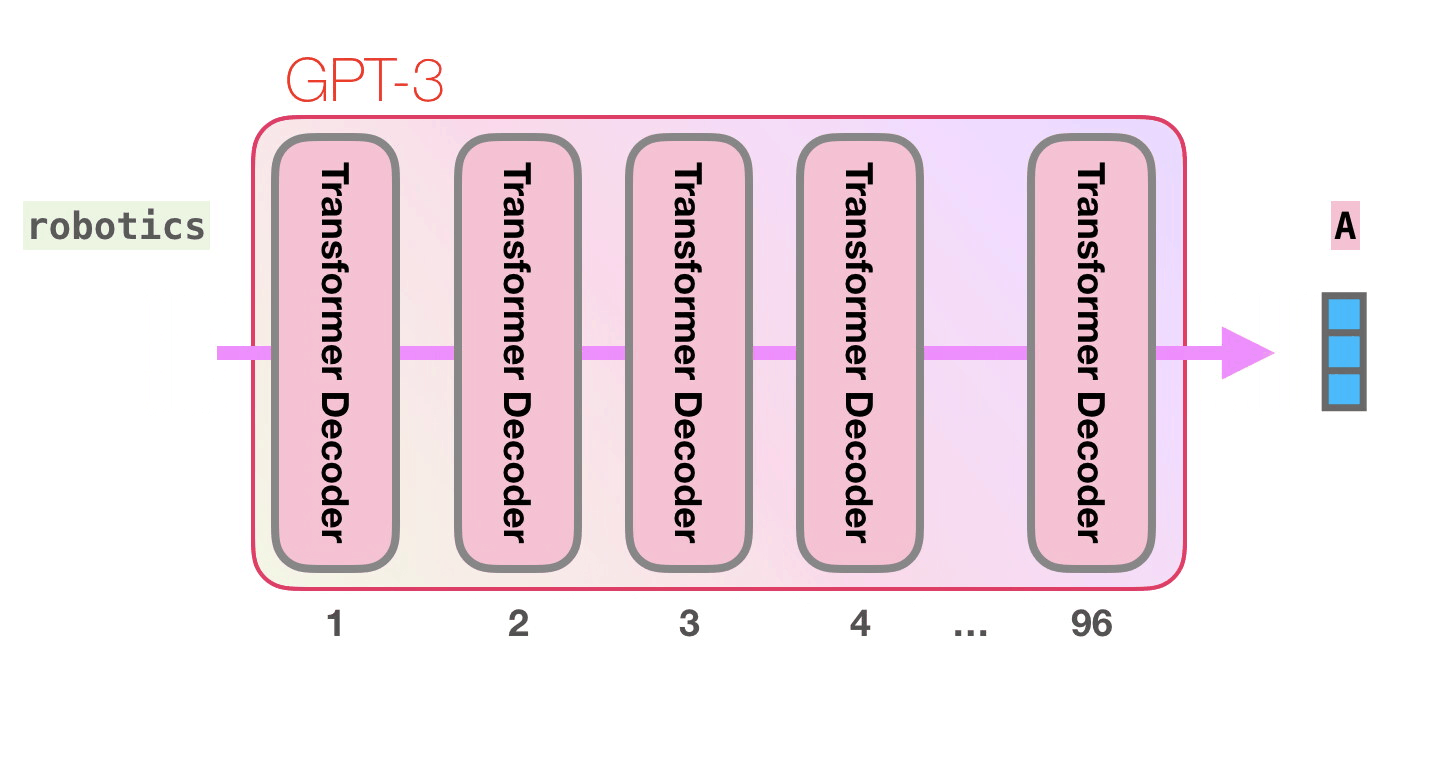
- 175 billion (1750억) parameters를 가진 거대 모델

- Transformer에서 Decoder, 그 안에서도 Multi-head attention이 제거된 Decoder block으로 이루어져있다.

| Motivation |
- 많은 unlabeled data로 task-agnostic한 model로 여러 NLP tasks를 해내자.
(NLP의 각 task마다 데이터셋을 모으고, 힘들게 labeling을 하고, 모델을 pretrain + finetuning 하지 말고,
fine-tuning을 하는데에도 비용이 많이 드니)
- 논문의 전체적인 내용이 model size와 model performance간의 관계가 power-law를 따른다는 것을 증명해보이려고 함
- 단순히 모델의 크기를 키운 것 만으로도 (attention이 약간 다르긴 하지만) task-agnostic model이 충분히 가능하다는 것을 증명
| Mixtured Datasets |
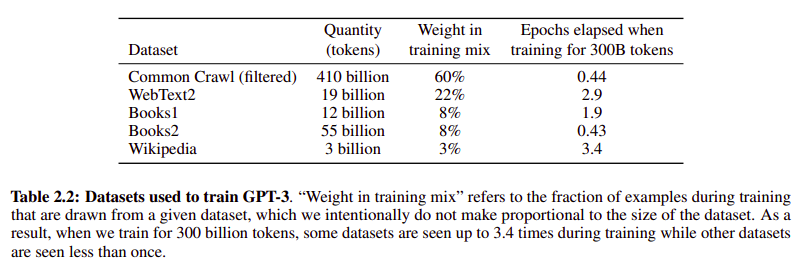
- Common Crawl : 거의 trillion개의 words를 가진 거대 데이터셋, 그러나 quality가 전반적으로 떨어져서 quality를 올려주는 과정을 거쳤다
1) original WebText (high-quality reference)를 Common Crawl 데이터셋과 분리하는 classifier를 훈련시킴
2) 1)의 classifier를 Common Crawl에 적용해서 resampling 한 결과를 사용
3) document별로 hashs를 10개씩 달아서, 많이 겹치는 document는 삭제했다 (deduplication)
4) high-quality reference corpora (WebText, Books, Wikipedia)를 추가
- 데이터셋의 수 자체는 Common Crawl이 많지만, 좋은 quality data를 넣어줬을 때의 성능이 더 좋았기 때문에
'Weight in training mix' 컬럼을 보면 수 자체는 더 적어도 high-quality인 데이터셋들이 힘을 쓸 수 있도록 mix를 구성했다
- 'Epochs elapsed when training for 300B tokens'를 보면, Common Crawl과 Books2는 각각 0.44, 0.43으로 각 데이터 전체를 쓰지 않았음을 알 수 있고
- 동시에 데이터셋 quality가 상대적으로 높은 WebText2, Books1, Wikipedia는 각각 2.9, 1.9, 3.4로 여러번 데이터셋 전체를 돌렸음을 볼 수 있다
- 거대 모델은 단순히 content를 기억해버리는 문제가 있어서, 이게 task를 contamination할 수 있으므로 overlaps를 최대한 없애려고 했으나, 버그 때문에 약간의 overlaps가 들어갔다..
| Zero, One, Few-Shot Learning |

- Meta-learning : learning to learn, 학습 방법을 학습한다
- 2개의 loops를 확인할 수 있다. 한 개는 outer loop (gradient update가 된다),
한 개는 in-context learning이라 부르는 inner loop
(gradient update가 안되기 때문에 실제 learning은 아니다)
- Fig. 1.1에서도 보이다시피 일관적인 input을 주면, 그 다음에 올 것을 model이 output으로 내는 형태
즉, input 자체가 task specification이 된다

- Fine-tuning은 example을 주면서 지속적으로 gradient update를 하고, 결과를 낸다. (GPT3는 이걸 하지 않았다)
- GPT3의 Approach는 Zero-Shot (0S) / One-Shot (1S) / Few-Shot Learning (FT)의 세 종류
- Zero-Shot : (Task description, prompt) 형태, 즉, (Translate English to French, cheese)로 들어간다.
즉, model이 추론을 하는데에 어떤 힌트가 될 수 있는 아무런 example도 주어지지 않음
- One-Shot : (Task description, example, prompt) 형태, 단 하나의 example이 주어진다
이때, 따로 example을 주지 않더라도, 내부적으로 들어가는 input은 모두 일관된 data
- Few-Shot : (Task description, example"s", prompt) 형태, 몇 개의 examples가 주어진다
examples 개수는, 10~100 사이에서 넣을 수 있는 만큼 (k=64, k=50.. 요런애들)
- 장점 : task-specific data의 필요성이 대폭 감소된다
- 단점 : 여전히 일부는 small task-specific한 data가 필요하고, 여전히 fine-tuned SOTA에 비하면 성능이 떨어진다
- 굳이 "one"-shot을 zero나 few와 굳이 분리한 이유는, 예시 하나를 주면 나머지를 해내는 '사람간 커뮤니케이션과 비슷하기' 때문
- training 과정은 fill-in-the-blank로 이루어졌다. e.g.) Sally started to sing a song when Jack ____ => left
예시에서 보이듯이 가장 마지막에 오는 것을 predict하는 형태
- Fine-tuning은 본 논문의 목적인 task-agnostic performance에 집중하기 위해서 하지 않았다 (future works)
| Performances |

- 모델의 크기가 커질수록, 더 좋은 성능
- Zero-, One-보다 Few-Shot이 더 잘한다
- Natural language prompt는 task가 뭔지 알려줬다는 것이고, (e.g. (add two numbers, 3+2 = ))
No prompt는 task에 대해서 안 알려줬다는 것이다 (e.g. 3+2 = )
- Zero-, One-에서는 prompt의 유무에 따라 성능차이가 좀 있는 걸 볼 수 있다
- Few-Shot에서도 처음엔 차이가 있었지만, 모델의 크기가 클수록 prompt의 유무와는 상관없이 잘했다
- 이 모든 과정에서 Gradient update도, Fine-tuning도 없었다 (no gradient update, no fine-tuning)

- 모델 파라미터가 클수록 (x축), Zero-, One-, Few-Shot 간 차이가 커지는 걸 볼 수 있다 (y축)
- 모델의 size에 따라 performance가 달라지는 걸 확인하기 위해서, 8종류의 모델을 사용하였다
- 모든 모델의 context-window는 2048 tokens
- 모든 모델은 3000억개의 tokens를 학습한다

n_(params) : trainable parameter의 전체 개수
n_(layers) : 레이어의 개수
d_(model) : 각 bottleneck 레이어 안에 있는 유닛 개수
n_(heads) : self-attention에서 사용하는 head의 개수
d_(head) : 각 head의 dimension
- optimizer는 Adam, cosine decay 사용, learning rate warmup 사용, weight decay는 0.1

- Training 디테일 : 모델 사이즈가 크면, 배치사이즈도 커야 하고, learning rate는 줄이자
- 배치사이즈는 Gradient noise로 guide를 해서 결정했다

- 8개 모델에 대한 훈련 곡선, parameters가 큰 모델 (더 옅은색) 일수록 power-law 곡선을 벗어나는 모습을 보인다
- 퍼포먼스는 대체적으로 power-law 트렌드를 따른다. (특히 낮은 파라미터의 보라색 선을 보면 잘 보인다)
Power-law (멱함수의 법칙)?


Specific한 Test 결과로는 News Article Generation 결과를 가져왔습니다.
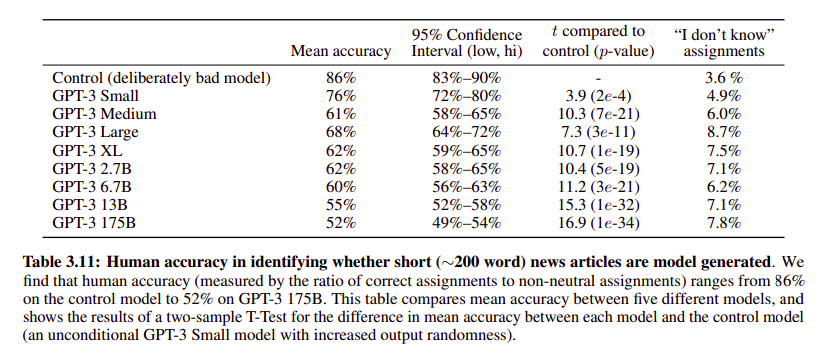
- 가장 큰 GPT3 175B의 결과를 보면 Confidence Interval이 49~54%로, 실제 사람이 쓴 것과 GPT3가 쓴 뉴스 기사를 반반의 확률로 사람이 구분해낼 수 있었음을 알 수 있다. 'I don't know'도 모델 크기에 따라 대체적으로 증가한 것을 볼 수 있다.
(binary classification인데 1/2의 확률이므로 실제적으로는 랜덤)

- 파라미터가 많을수록, Loss가 상대적으로 더 낮음
| Limitations |
성능이 많이 좋아졌지만, text synthesis와 몇몇 NLP tasks에서 취약한 점을 보였다
- text synthesis에서 동일한 말을 반복하거나, 내용이 길어지면 coherence (일관성)을 잃거나, 모순된 말을 하는 등의 문제
- 전문 dataset에 대해 좋은 결과를 내고도, common sense physics 질문에 취약한 모습을 보인다. 'If I put cheese into the fridge, will it melt (치즈를 냉장고에 넣으면, 녹을까?)'같은 질문에 고전했다
- AR이든 bidirectional 모델이든, 큰 모델이 가진 대체적인 문제가 제한적인 pretraining objective이다. 토큰별로 pretraining objective weight가 동일하게 주어짐에 따라, 무엇이 중요한지 무엇이 덜 중요한지를 잘 알지 못했다
- pre-training때 poor sample efficiency를 보이는 문제
- few-shot learning에서 불명확한 부분이 있는데, 모델이 inference를 할 때 바닥에서부터 new tasks를 배우는 것인지, 아니면 단순히 training때 배운 것을 기반으로 인식을 하는 것인지 알 수 없다
- structural & algorithmic limitation도 있는데, bidirectional의 이점을 포기했고, denoising같은 다른 training objectives도 포기했다. GPT3 사이즈의 bidirectional 모델, 더군다나 few-, zero-shot learning식으로 해보면 좋을 것 같다 (future works)
- 보편적인 딥러닝 모델의 문제점인 decision을 해석하는게 쉽지 않은 문제가 여전히 있다
- (거의 모든 task에 general하게 adapt하기 위한 broad skills를 모델이 갖고 있기에) computational cost가 많이 들고 (강필성 교수님 동영상에 의하면 약 51억원), inference가 불편하다는 문제점
| Fairness, Bias, and Representation |
수집한 데이터에 성차별, 인종차별 등의 bias

- 사용한 데이터셋에서 나타난 Gender issue
- 각각 He was very __ / She was very __ 에서 __ 부분을 추측한 것

- 인종차별적인 부분도 보였는데, Asian (파랑)은 무난한데 반해, Black (주황)에 대한 bad bias를 볼 수 있다
- 이외에 종교에 따른 차별도 있었다 (e.g. 기독교 키워드에 ignorant가 있거나, 유대교 키워드에 racist가 들어가는 등..)
- Energy usage : 학습 시에는 많은 에너지가 필요한데, 학습 이후에는 약간의 에너지만을 사용하므로 효율적으로 사용할 수 있다.
'Review of Papers' 카테고리의 다른 글
| [NLP] Character-Aware Neural Language Models (0) | 2021.12.05 |
|---|---|
| [NLP] RoBERTa : A Robustly Optimized BERT Pretraining Approach (0) | 2021.10.02 |
| [Tabular] TabNet : Attentive Interpretable Tabular Learning (0) | 2021.06.02 |
| [NLP] Character-Aware Neural Language Models (0) | 2019.10.29 |
| [NLP] Convolutional Neural Networs for Sentence Classification (0) | 2019.07.05 |



