
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 영어로전세계와소통하기
- 영어시험
- 링글경험담
- 소통챌린지
- Ringle
- 링글리뷰
- #영어공부
- 해외취업컨퍼런스
- CommunicateWiththeWorld
- 영어회화
- 링글
- 영어공부
- 링글커리어
- #직장인영어
- 뉴노멀챌린지
- 둔촌역장어
- #영어발음교정
- 오피스밋업
- 화상영어
- 총각네장어
- 성내동장어
- #Ringle
- 스몰토크
- #체험수업
- 장어랑고기같이
- 영어공부법
- #링글
- #nlp
- 강동구장어맛집
- #링글후기
- Today
- Total
Soohyun’s Machine-learning
[NLP] Convolutional Neural Networs for Sentence Classification 본문
[NLP] Convolutional Neural Networs for Sentence Classification
Alex_Rose 2019. 7. 5. 00:47
| Novelty |
1) very fast and strong with a single CNN layer (이전에도 CNN 쓴 논문들은 있었으나, 큰 효과를 보지는 못함)
2) pre-trained word vector 사용 (google negative300.bin download link)
| a summary of Abstract & Model architecture |
| We report on a series of experiments with CNN trained on top of pre-trained word vectors for sentence-level classification tasks. We show that a simple CNN with little hyperparameter tuning and static vectors achieves excellent results on multiple benchmarks. |

| Matrix for word vectors |
x : input vector
H : a filter size (h = [2,3,5])
N : a number of vocabulary
전처리 단계
1) concatenate a word vector to make a lookup table
x_(i) : word vector (one of the input)
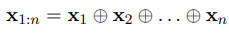
⊕ : concatenation operator
x_(i+j) : the concatenation of words x_(i), x_(i+1), ... , x_(i+j)
2) Conduct a convolution operation with filter w to make a feature c_(i)
w : a filter for convolution operation
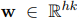
h : a window of h words (to produce a new feature)
k : the dimension of a word vector (in this case, 300)
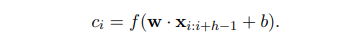
c_(i) : a feature (generated from a window of words x_(i:i+h-1) by the above equation)
f : a non-linear function
3) make a feature map with each feature c_(i)
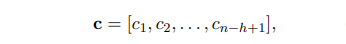
c is a subset of R^(n-h+1)
4) apply a max-over-time pooling over the feature map c
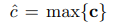
maximum value c_hat as the feature corresponding to this particular filter.
(The idea is to capture the most important feature - one with the highest value - for each feature map.)
These features form the penultimate layer and are passed to a fully connected softmax layer whose output is the probability distribution over labels.
위의 penultimate layer라는게 dropout을 말하는거 같다. dropout을 주면서, L2-norms을 weight vectors에 줬음.
(여기서 weight vectors는 W를 말하는 듯. 이후 수식을 보면..)

각 feature에서 max 값만을 취하기 때문에, filter의 개수인 m개 대로 penultimate layer z가 형성되는 듯(...) 한데 뭔가 딱 와닿진 않음

사용한 데이터셋과 experimental setup
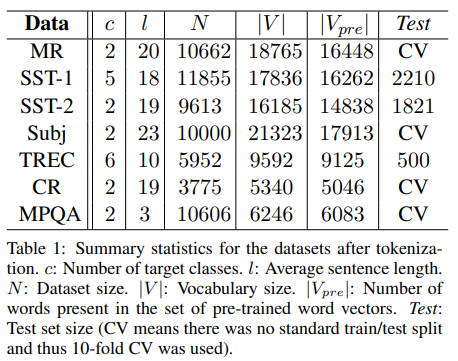
1) MR : 무비 리뷰 셋. positive/negative 분류 (binary)
2) SST-1 : Stanford Sentiment Treebank -1, 위의 MR의 extension이지만 train/dev/test로 나눠져 있고, labels도 더 세부적이다. (very positive / positive / neutral / negative / very negative)
3) SST-2 : Stanford SEntiment Treebank -2, SST-1과 같지만 neutral이 사라지고, positive/negative의 binary labels
4) Subj : Subjectivity dataset으로 문장이 subjective한지 objective한지를 classification (????)
5) TREC : TREC question dataset, 질문 문장을 5 종류의 질문 타입으로 나누는 것. (사람에 대한 질문인지, 장소에 대한 질문인지, 숫자 정보인지 등등)
6) CR : 다양한 상품들에 대한 Customer Reviews를 모아놓은 것. positive/negative를 구분한다.
7) MPQA : Opinion polarity detection
Hyperparameters and Training
mini-batch size = 50 (shuffled, and randomly select 10% of training data as the dev set)
gradient check : SGD + Adadelta
filter windows (h) = [3,4,5] with 100 features maps each
activation function : ReLU
dropout rate : 0.5
L2 constraint (s) = 3
pre-trained vectors는 구글의 negative-300.bin 사용
때문에 vector dim은 30
oov는 initialized randomly
Model variants
1) CNN-rand
2) CNN-static
3) CNN-non-static
4) CNN-multi-channel
cv-fold는 한 애들은 항상 10-fold
unknown word vectors의 init은 uniform distribution으로 해줌
Multi-Channel vs. Single Channel Models
multi-channel은 single channel model보다 좋은 성능을 보여주었지만..

그럼에도 불구, 결과는 single (static or non-static) / multichannel 각각이 mixed 형태로 나타났다.
그리고 이후에 fine-tuning process를 regularizing하기 위한 이후 작업이 필요하다.
한 예시로, non-static portion을 위한 추가 channel을 사용하는 대신,
single channel을 유지하고 training 과정 동안, extra dimensions 를 사용하게 했다.
(한 예시로~ 이후부터 나온 내용이 regularizing과 어떤 관련이 있는건지 잘 모르겠다.)
Static vs. Non-static Representations

'Review of Papers' 카테고리의 다른 글
| [NLP] Character-Aware Neural Language Models (0) | 2021.12.05 |
|---|---|
| [NLP] RoBERTa : A Robustly Optimized BERT Pretraining Approach (0) | 2021.10.02 |
| [NLP][GPT3] Language Models are Few-Shot Learners (0) | 2021.08.07 |
| [Tabular] TabNet : Attentive Interpretable Tabular Learning (0) | 2021.06.02 |
| [NLP] Character-Aware Neural Language Models (0) | 2019.10.29 |



