
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 총각네장어
- #링글
- #체험수업
- #링글후기
- 영어시험
- #영어공부
- 링글커리어
- 영어공부법
- #Ringle
- 성내동장어
- 링글경험담
- 소통챌린지
- 영어회화
- #직장인영어
- 강동구장어맛집
- #nlp
- 뉴노멀챌린지
- Ringle
- 영어공부
- CommunicateWiththeWorld
- 화상영어
- #영어발음교정
- 영어로전세계와소통하기
- 링글리뷰
- 링글
- 둔촌역장어
- 장어랑고기같이
- 오피스밋업
- 해외취업컨퍼런스
- 스몰토크
- Today
- Total
Soohyun’s Machine-learning
[NLP] Character-Aware Neural Language Models 본문

| Contribution |
character level의 embedding을 통해 word-level language model의 성능을 향상하는 방법을 제시했다. (네트워크 자체는 당시 보편적인 걸 사용했지만, input으로 char-level을 사용함으로써 word-level embedding이 정말 필요한 것인가-라는 의문을 제기한다. 영어, 체코어, 독일어, 스페인어, 불어, 러시아어, 아랍어 데이터셋으로 실험을 진행했다. 형태소가 풍부한 언어일수록 성능차이가 word-level 대비 더 좋게 나왔다. 여기까지가 장점이며 단점으로는 성능은 괜찮지만 char-level 자체가 efficiency - time tradeoff가 있다.) |
| Abstract |
우리는 오로지 Char-level inputs에만 의존하는 simple neural language mpodel을 설명할 것이다. (다음 단어에 대한) predictions는 여전히 word-level에서 이루어진다. our model은 characters에 대한 CNN과 Highway network를 사용한다. 이 output은 LSTM으로 들어간다. English Penn Treebank (PTB) 데이터셋에서 이 모델은 60% 더 적은 파라미터에도 현존하는 SOTA (2015년도 기준)에 준하는 성능을 보였다. 형태가 다양한 언어들(rich morphology - 아랍어, 체코어, 프랑스어, 독일어, 스페인어, 러시아어)에서 이 모델은 word-level/morpheme-level (단어 레벨/형태소 레벨) LSTM baseline을 outperform한다. 여전히 더 적은 파라미터들에도 불구하고 논문의 결과는 많은 언어들에서, language modeling (언어 모델링)에 character inputs가 sufficient하다는 걸 시사(suggest)한다. |
본 논문의 모델의 Task는 next word prediction이다.

요약본 - epoch은 아랍어가 아니라면 25번, 아랍어만 30번 - 백프로파게이션은 35 time steps만 진행 (코드로 보면 sentence 길이가 35가 넘어가면 자름) - Learning rate는 1로 시작해서 0.5 weight decay - 모델의 파라미터들은 [-0.05, 0.05]의 uniform distribution으로 random initialization - drop out = 0.5 (다만 Highway network -> LSTM으로 최초로 갔을땐 dropout 적용을 안 함) - Gradient norm = 5 (5가 넘어가면 다시 5로 renormalization) - Hierarchical Softmax는 데이터 사이즈를 키웠을때 (DATA-L)에만 적용해주었다. DATA-S 상태에서는 효과가 없었다 |
|
| 1. Preprocessing 단계 | 데이터셋은 언어별로 다르며, 영어의 경우 Penn Tree Bank 데이터셋 (Mikolov가 전처리한 버전, vocabulary size가 10K) 사용 3종류의 embedding matrices를 사용 1) character-level embedding matrix (input으로 들어갈땐 word 형태로 들어감, 이 논문의 contribution) 2) word-level embedding matrix (비교를 위해서) 3) morpheme matrix (prefix(접두사) + stem(어간) + suffix(접미사)) + word-level embedding matrix 여기서 3)번의 morpheme matrix는 morphemes를 얻기 위해서 Morfessor Cat-MAP(Creutz and Lagus 2007, unsupervised morphological tagger)을 썼다고 함. |
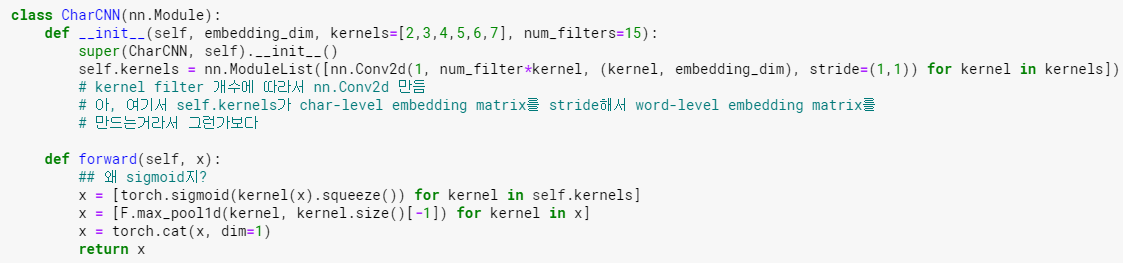
| 2. CharCNN | 1) CNN 코드상의 kernel width w = [1,2,3,4,5,6,7] (large model 기준, small model은 1~6까지만)이고 height는 15-dim이다. hidden 수는 [50,100,150,200,200,200,200] 2) 각 Convolution 마다 max값을 취하고, 그렇게 한 번 stride 하고 tanh를 적용시켜주고 나면, 첫번째 필터에 대한 max값들의 모음인 vector 하나가 나온다. 이 vector의 max값을 다시 취한다. 3) max값끼리 concatenate를 한다. 이렇게 나온 벡터가 뒤의 Highway Network의 input이 된다. |
| 3. Highway Network | 다른 논문에서는 x였던 것을 여기에서는 CharCNN의 output값인 y를 넣어준다. 1) y를 받아서 affine transformation W_(T) * y + b_(T) 연산을 해준다. (임베딩 행렬 x 인풋 + 바이어스) 2) 1)의 결과값에 Sigmoid를 씌운다. 이 값이 transform gate t가 된다. 3) 2)의 값과 ReLU(W_(H) * y + b_(H))를 element-wise product를 해준다. 4) 다음으로 (1 - t) 즉, 숫자 1에서 2)의 결과값을 빼준다. 이게 carry gate이다. 5) 4)번의 carry gate와 y를 곱해준다. 6) 마지막으로 3)의 값과 5)의 값을 더해서 LSTM으로 보낸다. - 위의 W_(T)와 W_(H)는 모두 연산의 편리성을 위해 square matrix(정방 행렬)이며, 파이토치 코드로는 nn.Linear(dim, dim)이 된다. - Highway Network의 bias들은 -2 (마이너스 2)로 들어감 - 레이어의 개수는 2개가 좋다. 그 이상으로 늘려도 더 효과가 없음 - 이 논문에서 Highway network는 semantic features를 아는 것 같다고 함 (character-level input을 더 의미있게 만들어줌. 왜냐하면 여기를 통과하기전 상태에서는 단어의 외부적인 모습 --you, your, young 등등--을 인식한 모습을 보여주는데, Highway를 통과한 이후에는 you, we 같은 semantic한 것들도 잡아내기 때문. 이는 통과하기 전과 통과한 후에 Nearest Neighbor를 적용해서 체크했다) - Ax + b 형태의 수식 자체가 affine transformation이다. Ax는 그냥 선형이고, b가 있어야 affine transform. |
| 4. LSTM | |
| Character-level Convolutional Neural Network |
| t : timestep | [someone, has, a, dream, ...] |
| C : vocabulary of characters | the size of character embeddings : 15 (논문 & 코드) |
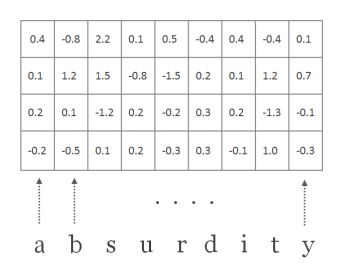
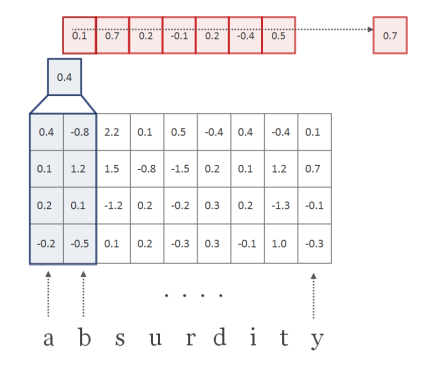
| d : the dimensionality of character embeddings | 논문에 쓰인 d는 15차원, 만약에 word k = ['k','n','o','w']라면 길이 l(small L)=4, embedding dimension d는 15로, 'know'에 대한 character-level embedding vector의 차원은 15 by 4의 column vector (또는 4 by 15의 row vector) (assumption) embedding시의 vector initialization은 random하게 준다. |
| Q : R^(d x |C|), matrix character embeddings | |C|는 cardinality of vocabulary of all characters Q는 전체 words에 대한 character embedding이 있는 matrix |
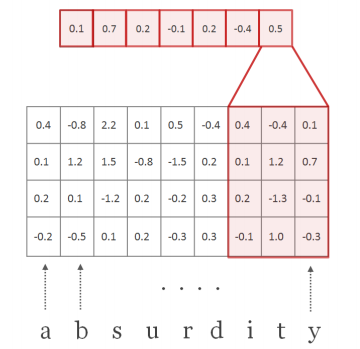
| C^(k) : word k에 대한 matrix of character embedding | word의 character 개수가 5개라면, 15 x 65(max_word_length)의 matrix가 됨. 가장 긴 단어의 길이에 맞춰서 zero padding이 들어가고, START, END,<EOS>가 전부 들어간다. 여기서 STAR/END는 단어의 시작/끝이고, EOS는 raw data input이 sentence로 들어오기 때문에 필요한 것. |
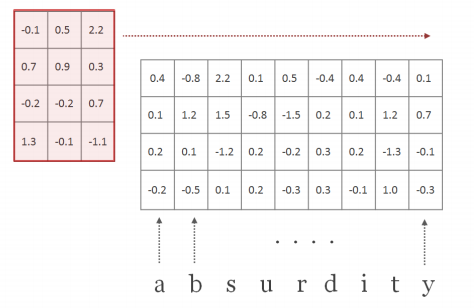
| H : filter (=kernel), H ∈ R^(d x w) | w = conv filter의 width. w = [1,2,3,4,5,6,7] (large 기준) d x w 즉, [15 x 1], [15 x 2], [15 x 3], [15 x 4], [15 x 5], [15 x 6], [15 x 7]의 H 커널 매트릭스가 모든 단어에 대해 곱해짐. 이때 Frobenius inner product를 썼다고 되어 있는데, 2차원에서는 element-wise product와의 차이를 모르겠음. |
| f^(k) ∈ R^(l-w+1) : a feature map | |
| h (small h) | the hidden size of kernels : 650 (=h, Large 모델 기준) |
feature map f가 만들어지는 과정


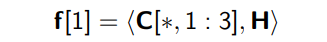

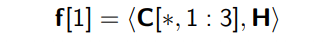
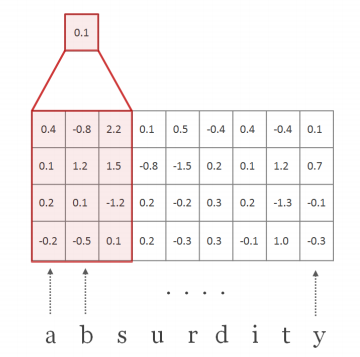
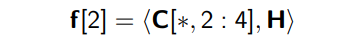
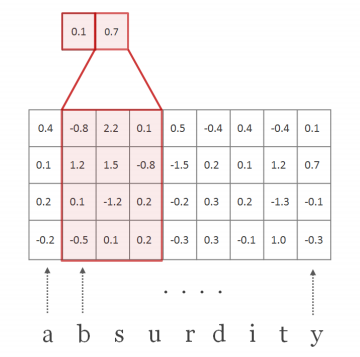
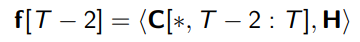
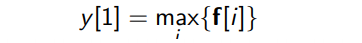



코드 예시
##왜 sigmoid지? -> 당연히 해줘야 하는 부분. 논문에서 non-linear function을 sigmoid, tanh, relu로 다 썼다.
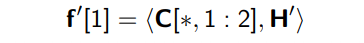

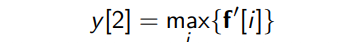
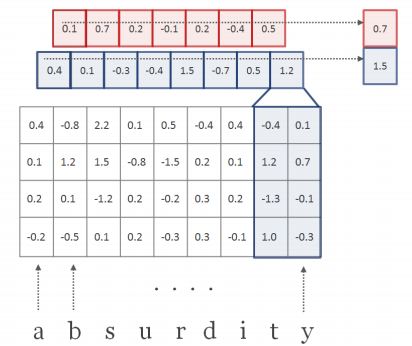
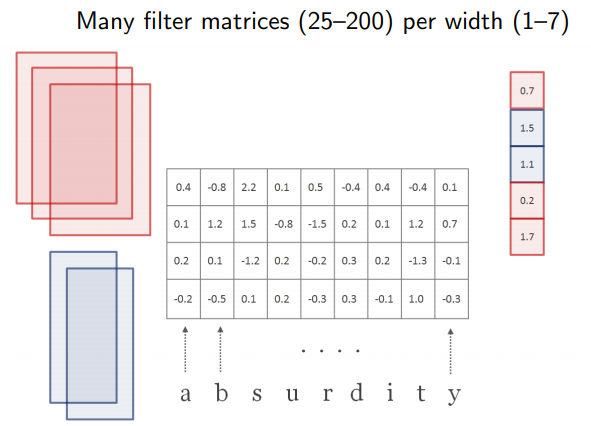


이렇게 해서 나온 결과가 y^(k) : vector 맞음, y도 벡터이며 y^(k)는 특정한 단어 k에 대한 matrix representation이라는 걸 나타내려고 한 것 같다.
| Highway network |
We could simply replace x^(k) with y^(k) at each t in the RNN-LM.
y : output from CharCNN
By construction, the dimensions of y and z have to match, and hence W_(T) and W_(H) are square matrices.

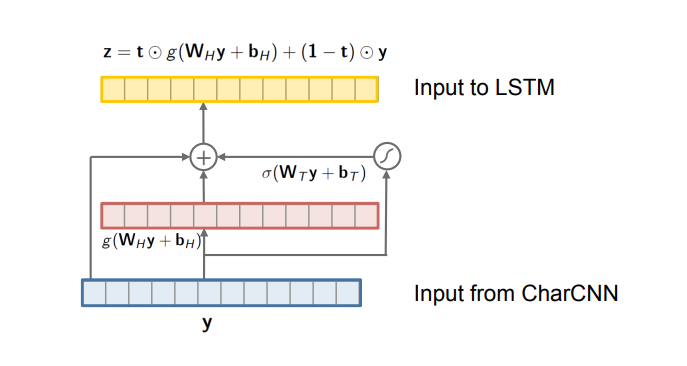

self.Wh = nn.Linear... 인 이유는 Wh * y + bh의 affine transformation이기 때문인듯.
Q. 이 코드에서 word_dim * word_dim인 이유는? W는 차원을 맞춰주려고 h든 t든 모두 square matrix이기 때문. 코드로는 nn.Linear(word_dim, word_dim)
transform_gate는 non-linear (torch.sigmoid) 들어갔고
carry_gate도 1에서 transform_gate 값을 빼주는 것도 맞고
여기서 x는 아마도 CharCNN의 return인 x (논문에서는 y)
위의 네트워크 그림에서 LSTM으로 들어가는 선이 3개라서, return의 2개가 좀 부족하지 않나.. 싶은데, 그냥 y라서 따로 네트워크를 구축할 필요는 없는 듯.


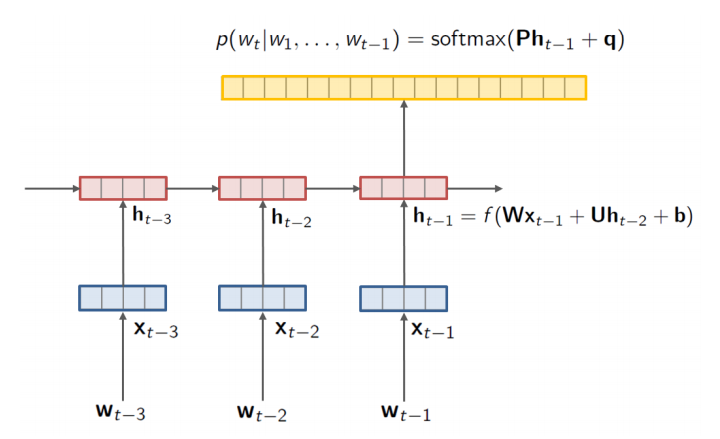
| Recurrent Neural Network Language Model |
V : fixed size of vocabulary of words
P : output embedding matrix (p : output embedding)
p^(j) : output word embedding (이건 또 뭔 임베딩임 -> Highway Network의 아웃풋을 LSTM으로 넣어줄때의 임베딩인가???)
q : bias term (앞에선 b였는데... 같은 논문 안에서 notation이 바뀌나???
g : composition function
Our model simply replaces the input embeddings X with the output from a character-level convolutional neural network.

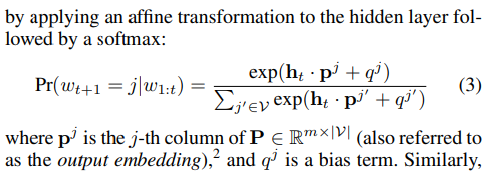

| Baselines |

CharacterRNNLM

이 코드의 마지막 부분에서 Classifier가 왜 들어가지? classifier가 왜 필요하지??

| Optimization |


Dropout (드롭아웃)

gradient norm이 gradient clipping맞나? gradient clipping이 왜 crucial하지?? gradient explosion을 방지해줘서??
Hierarchical softmax (계층적 소프트맥스)

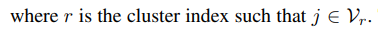
수식의 첫번째 텀은 the probability of picking 클러스터 r
두번째 텀은 the probability of picking 단어 j (주어진 cluster r이 선택되었을 때)
We found that hierarchical softmax was not necessary for models train on DATA-S.
(왜 효과가 없었을까? Data가 가진 complexity가 hsm 대비 낮았던 것 같다)
| References |
| 1) https://www.quantumdl.com/entry/3%EC%A3%BC%EC%B0%A81-CharacterAware-Neural-Language-Models |
| 2) http://web.stanford.edu/class/cs224n/ |
'Review of Papers' 카테고리의 다른 글
| [NLP] Character-Aware Neural Language Models (0) | 2021.12.05 |
|---|---|
| [NLP] RoBERTa : A Robustly Optimized BERT Pretraining Approach (0) | 2021.10.02 |
| [NLP][GPT3] Language Models are Few-Shot Learners (0) | 2021.08.07 |
| [Tabular] TabNet : Attentive Interpretable Tabular Learning (0) | 2021.06.02 |
| [NLP] Convolutional Neural Networs for Sentence Classification (0) | 2019.07.05 |



